Artificial intelligence has infiltrated all aspects of our lives and brought significant improvements.
Although the first thing that comes to most people’s minds when they think about AI are humanoid robots or intelligent machines from sci-fi flicks, this technology has had the most impressive advancements in the field of data science.
Big data analytics is what has already transformed the way we do business as it provides an unprecedented insight into a vast amount of unstructured, semi-structured, and structured data by analyzing, processing, and interpreting it.
Data and AI specialists and researchers are likely to have a field day in 2020, so here are some of the most important trends in this industry.
1. Predictive Analytics
As its name suggests, this trend will be all about using gargantuan data sets in order to predict outcomes and results.
This practice is slated to become one of the biggest trends in 2020 because it will help businesses improve their processes tremendously. It will find its place in optimizing customer support, pricing, supply chain, recruitment, and retail sales, to name just a few.
For example, Amazon has already been leveraging predictive analytics for its dynamic pricing model. Namely, the online retail giant uses this technology to analyze the demand for a particular product, competitors’ prices, and a number of other parameters in order to adjust its price.
According to stats, Amazon changes prices 2.5 million times a day so that a particular product’s cost fluctuates and changes every 10 minutes, which requires an extremely predictive analytics algorithm.
2. Improved Cybersecurity
In a world of advanced technologies where IoT and remotely controlled devices having top-notch protection is of critical importance.
Numerous businesses and individuals have fallen victim to ruthless criminals who can steal sensitive data or wipe out entire bank accounts. Even some big and powerful companies suffered huge financial and reputation blows due to cyber attacks they were subjected to.
This kind of crime is particularly harsh for small and medium businesses. Stats say that 60% of SMBs are forced to close down after being hit by such an attack.
AI again takes advantage of its immense potential for analyzing and processing data from different sources quickly and accurately. That’s why it’s capable of assisting cybersecurity specialists in predicting and preventing attacks.
In case that an attack emerges, the response time is significantly shorter, so that the worst-case scenario can be avoided.
When we’re talking about avoiding security risks, AI can improve enterprise risk management, too, by providing guidance and assisting risk management professionals.
3. Digital Workers
In 2020, an army of digital workers will transform the traditional workspace and take productivity to a whole new level.
Virtual assistants and chatbots are some examples of already existing digital workers, but it will be even more of them. According to research, this trend is one the rise, as it’s expected that AI software and robots will increase by 50% by 2022.
Robots will take over even some small tasks in the office. The point is to streamline the entire business process, and that can be achieved by training robots to perform small and simple tasks like human employees. The only difference will be that digital workers will do that faster and without any mistakes.
4. Hybrid Workforce
Many people worry that AI and automation will steal their jobs and render them unemployed.
Even the stats are bleak – AI will eliminate 1.8 million jobs. But, on the other hand, it will create 2.3 million new jobs.
So, our future is actually AI and humans working together, and that’s what will become the business normalcy in 2020.
Robotic process automation and different office digital workers will be in charge of tedious and repetitive tasks, while more sophisticated issues that require critical thinking and creativity will be human workers’ responsibility.
One of the most important things about creating this hybrid workforce is for businesses to openly discuss it with their employees and explain how these new technologies will be used. A regular workforce has to know that they will be working alongside machines whose job will be to speed up the processes and cut costs.
5. Process Intelligence
This AI trend will allow businesses to gain insight into their processes by using all the information contained in their system and creating an overall, real-time, and accurate visual model of all the processes.
What’s great about it is that it’s possible to see these processes from different perspectives – across departments, functions, staff, and locations.
With such a visual model, it’s possible to properly analyze these processes, identify potential bottlenecks, and eliminate them before they even begin to emerge.
Besides, as this is AI and data analytics at their best, this technology will also facilitate decision-making by predicting the future results of tech investments.
Needless to say, Process Intelligence will become an enterprise standard very soon, thanks to its ability to provide a better understanding and effective management of end-to-end processes.
As you can see, in 2020, these two advanced technologies will continue to evolve and transform the business landscape and change it for the better.





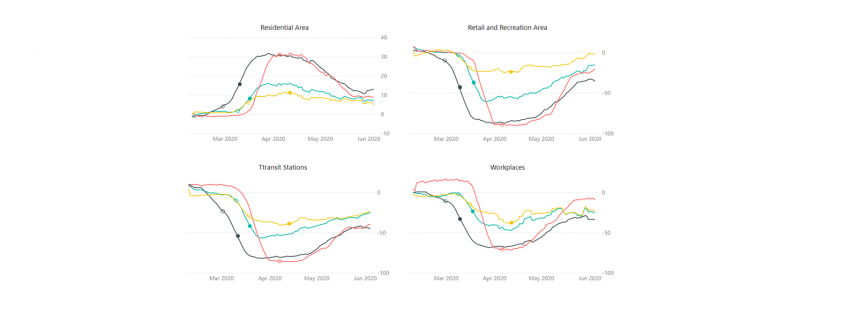
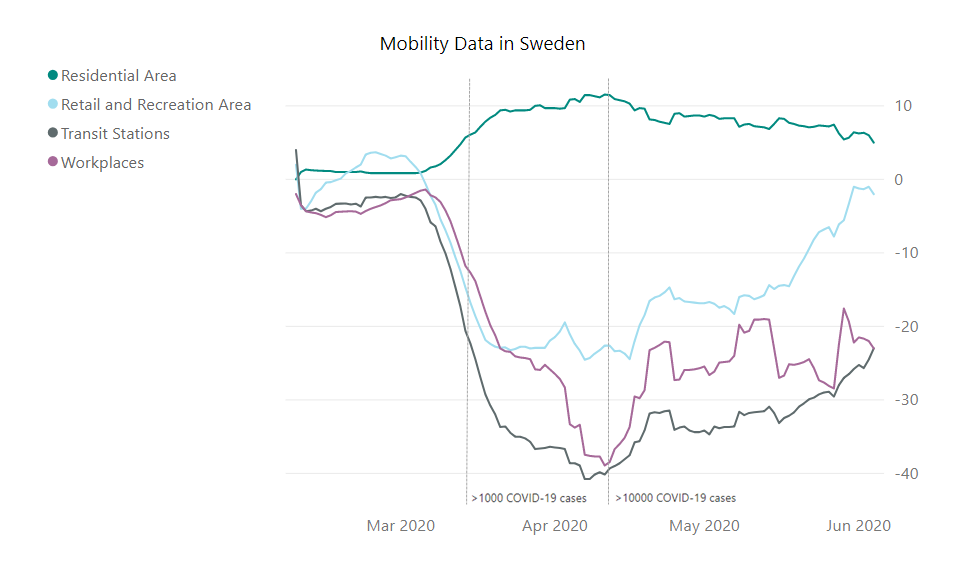
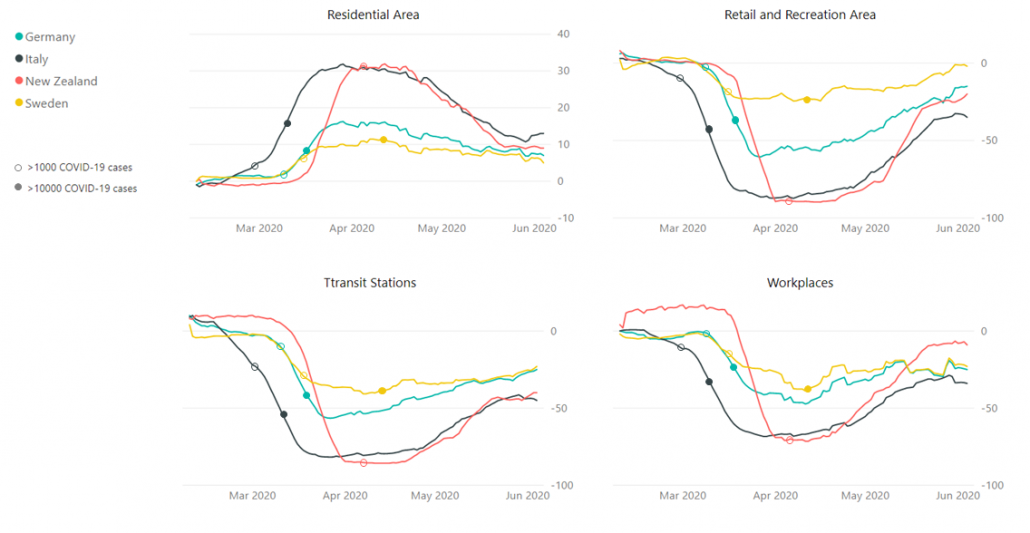
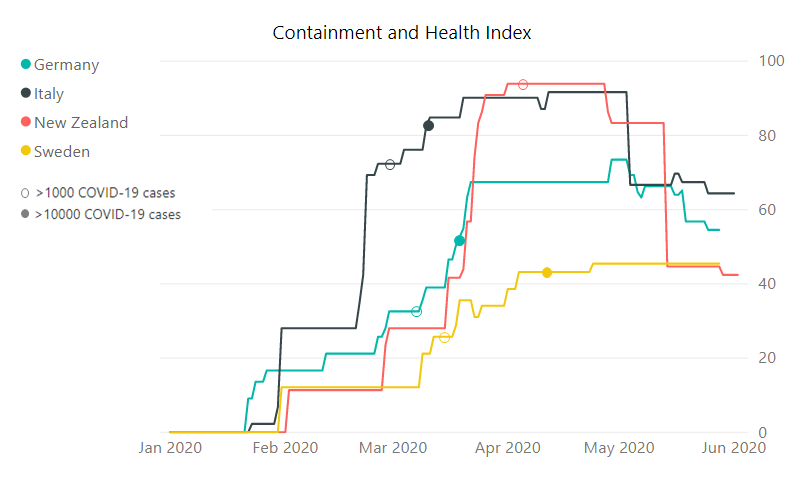



 Ronny Fehling is Partner and Associate Director for Artificial Intelligence as the Boston Consulting Group GAMMA. With more than 20 years of continually progressive experience in leading business and technology innovation, spearheading digital transformation, and aligning the corporate strategy with Artificial Intelligence he industry-leading organizations to grow their top-line and kick-start their digital transformation.
Ronny Fehling is Partner and Associate Director for Artificial Intelligence as the Boston Consulting Group GAMMA. With more than 20 years of continually progressive experience in leading business and technology innovation, spearheading digital transformation, and aligning the corporate strategy with Artificial Intelligence he industry-leading organizations to grow their top-line and kick-start their digital transformation.



 David M. Raab is as a consultant specialized in marketing software and service vendor selection, marketing analytics and marketing technology assessment. Furthermore he is the founder of the Customer Data Platform Institute which is a vendor-neutral educational project to help marketers build a unified customer view that is available to all of their company systems.
David M. Raab is as a consultant specialized in marketing software and service vendor selection, marketing analytics and marketing technology assessment. Furthermore he is the founder of the Customer Data Platform Institute which is a vendor-neutral educational project to help marketers build a unified customer view that is available to all of their company systems.