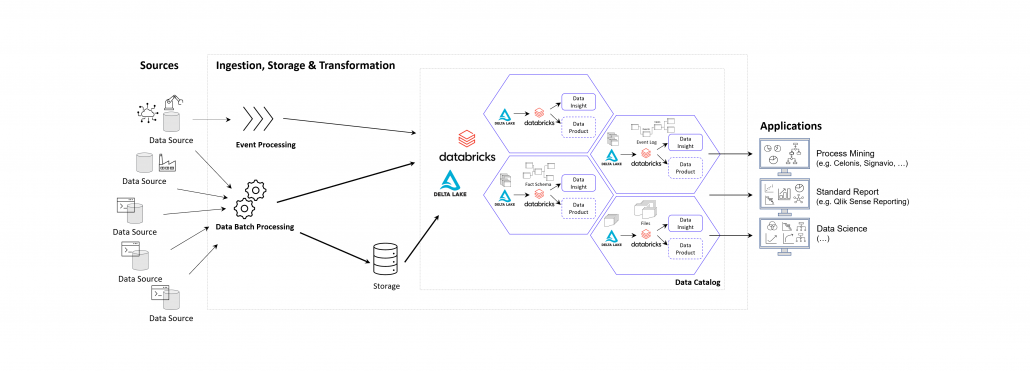
Data Mesh Architecture on Cloud for BI, Data Science and Process Mining
Companies use Business Intelligence (BI), Data Science, and Process Mining to leverage data for better decision-making, improve operational efficiency, and gain a competitive edge. BI provides real-time data analysis and performance monitoring, while Data Science enables a deep dive into dependencies in data with data mining and automates decision making with predictive analytics and personalized customer experiences. Process Mining offers process transparency, compliance insights, and process optimization. The integration of these technologies helps companies harness data for growth and efficiency.
Applications of BI, Data Science and Process Mining grow together
More and more all these disciplines are growing together as they need to be combined in order to get the best insights. So while Process Mining can be seen as a subpart of BI while both are using Machine Learning for better analytical results. Furthermore all theses analytical methods need more or less the same data sources and even the same datasets again and again.
Bring separate(d) applications together with Data Mesh
While all these analytical concepts grow together, they are often still seen as separated applications. There often remains the question of responsibility in a big organization. If this responsibility is decided as not being a central one, Data Mesh could be a solution.
Data Mesh is an architectural approach for managing data within organizations. It advocates decentralizing data ownership to domain-oriented teams. Each team becomes responsible for its Data Products, and a self-serve data infrastructure is established. This enables scalability, agility, and improved data quality while promoting data democratization.
In the context of a Data Mesh, a Data Product refers to a valuable dataset or data service that is managed and owned by a specific domain-oriented team within an organization. It is one of the key concepts in the Data Mesh architecture, where data ownership and responsibility are distributed across domain teams rather than centralized in a single data team.
A Data Product can take various forms, depending on the domain’s requirements and the data it manages. It could be a curated dataset, a machine learning model, an API that exposes data, a real-time data stream, a data visualization dashboard, or any other data-related asset that provides value to the organization.
However, successful implementation requires addressing cultural, governance, and technological aspects. One of this aspect is the cloud architecture for the realization of Data Mesh.
Example of a Data Mesh on Microsoft Azure Cloud using Databricks
The following image shows an example of a Data Mesh created and managed by DATANOMIQ for an organization which uses and re-uses datasets from various data sources (ERP, CRM, DMS, IoT,..) in order to provide the data as well as suitable data models as data products to applications of Data Science, Process Mining (Celonis, UiPath, Signavio & more) and Business Intelligence (Tableau, Power BI, Qlik & more).
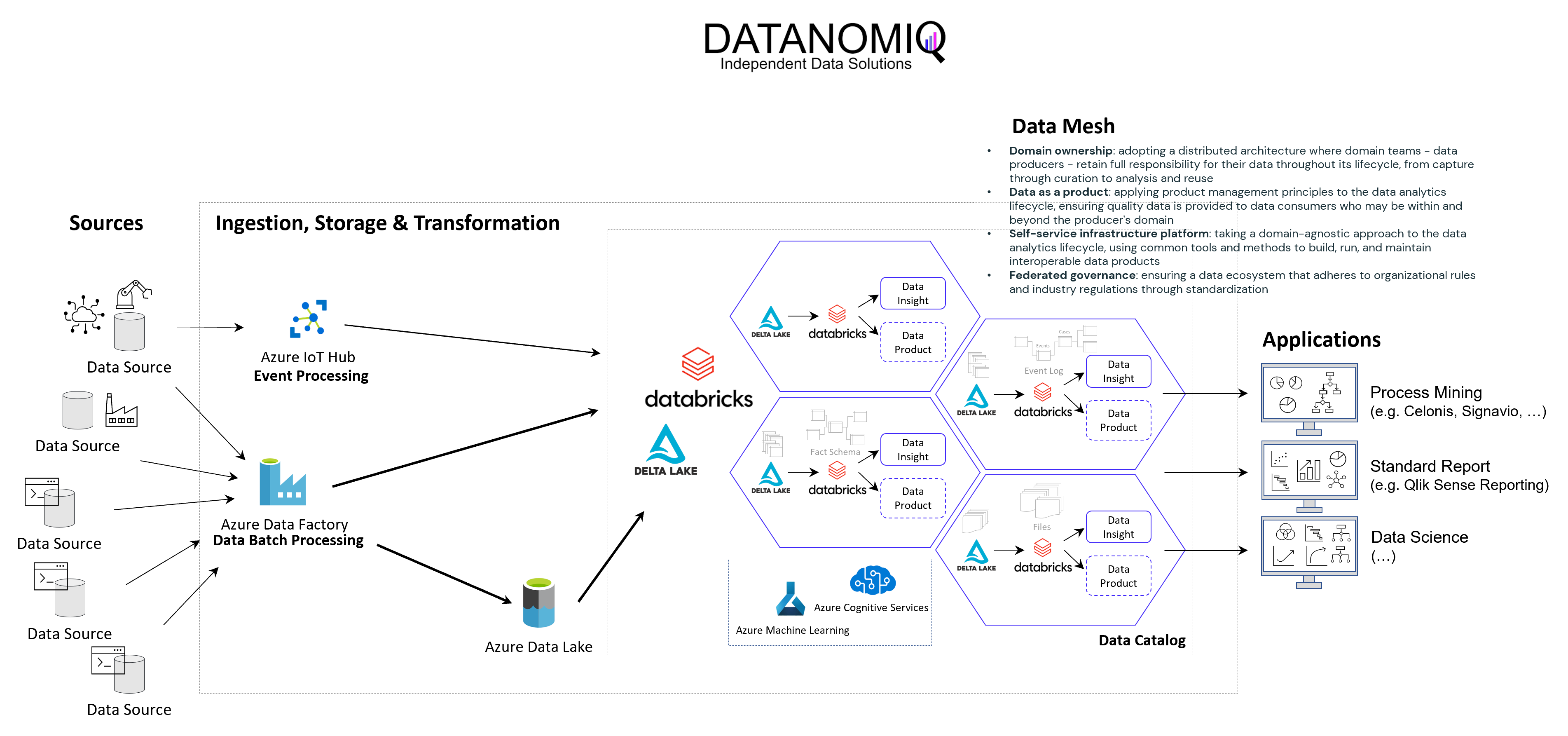
Data Mesh on Azure Cloud with Databricks and Delta Lake for Applications of Business Intelligence, Data Science and Process Mining.
Microsoft Azure Cloud is favored by many companies, especially for European industrial companies, due to its scalability, flexibility, and industry-specific solutions. It offers robust IoT and edge computing capabilities, advanced data analytics, and AI services. Azure’s strong focus on security, compliance, and global presence, along with hybrid cloud capabilities and cost management tools, make it an ideal choice for industrial firms seeking to modernize, innovate, and improve efficiency. However, this concept on the Azure Cloud is just an example and can easily be implemented on the Google Cloud (GCP), Amazon Cloud (AWS) and now even on the SAP Cloud (Datasphere) using Databricks.
Databricks is an ideal tool for realizing a Data Mesh due to its unified data platform, scalability, and performance. It enables data collaboration and sharing, supports Delta Lake for data quality, and ensures robust data governance and security. With real-time analytics, machine learning integration, and data visualization capabilities, Databricks facilitates the implementation of a decentralized, domain-oriented data architecture we need for Data Mesh.
Furthermore there are also alternate architectures without Databricks but more cloud-specific resources possible, for Microsoft Azure e.g. using Azure Synapse instead. See this as an example which has many possible alternatives.
Summary – What value can you expect?
With the concept of Data Mesh you will be able to access all your organizational internal and external data sources once and provides the data as several data models for all your analytical applications. The data models are seen as data products with defined value, costs and ownership. Each applications has its own data model. While Data Science Applications have more raw data, BI applications get their well prepared star schema galaxy models, and Process Mining apps get normalized event logs. Using data sharing (in Databricks: Delta Sharing) data products or single datasets can be shared through applications and owners.







Leave a Reply
Want to join the discussion?Feel free to contribute!