3 Types of Preventative Maintenance for Data Centers
Image Source: source unsplash.com
Downtime for a data center can be extraordinarily costly — potentially leading to lost revenue, lost customers and a damaged reputation. Preventative maintenance (PM) helps keep essential data center equipment running for as long as possible (while also making potential issues easier to spot).
However, there are many strategies for preventative maintenance that a data center can use, and not every strategy will be right for every center.
These are 3 types of preventative maintenance that businesses can use to maximize data center uptime and extend the lifespan of key equipment.
What Is Preventative Maintenance?
With preventative maintenance, an asset owner performs regularly scheduled maintenance activities in order to prevent future failures, downtime or unplanned repairs. Regardless of industry, preventative maintenance tasks always have a few characteristics in common:
- The maintenance is systematic, meaning it is done according to a pre-established plan or method.
- The maintenance is regular, meaning it occurs at predetermined intervals.
- The maintenance is preventative, meaning that it is intended to prevent failures and unplanned repairs.
Any effective PM strategy requires coordination, documentation and scheduling. Managers will need to gather information on asset performance, develop a maintenance strategy and ensure that maintenance is being both properly performed and occurring at regular intervals.
Common examples of maintenance tasks in a data center include the physical inspection of servers, the review of server logs and software updates.
1. Time-Based/Calendar-Based Preventative Maintenance
Calendar-based maintenance occurs at a specific time, based on a calendar interval. For example, a data center may schedule a regular visual inspection of server vents to occur daily, weekly, or monthly. The same data center may also schedule bi-monthly backups of key digital assets.
Intervals are generally determined based on the maintenance task being performed and a combination of historical performance data and industry best practices.
A data center may determine its inspection schedule based on recommendations from business partners, experience with past failures and data on equipment performance that can show when equipment performance begins to degrade without maintenance or inspections.
These intervals will be a part of the data center’s overall maintenance plan and should be regularly reviewed to ensure that maintenance isn’t occurring too often or too infrequently.
Particularly intensive maintenance tasks — anything that requires a great deal of time, requires the disassembly or important equipment or requires that servers be taken offline — may need to be scheduled less frequently to balance the benefits of PM against the potential costs, like downtime.
2. Usage-Based Preventative Maintenance
With a usage-based PM strategy, maintenance tasks occur based on how frequently equipment is used. Instead of occurring automatically once enough time has passed, usage-based tasks only trigger when an asset has been online for long enough or experienced enough exposure to certain environmental conditions.
Usage-based PM is most useful for assets that are not used continuously. These assets may not degrade as quickly as assets that are used regularly or always online.
Some time-based maintenance may still be necessary for assets that otherwise benefit from usage-based maintenance. Components or equipment kept in storage can degrade over time due to environmental conditions like dust, UV or moisture. Inspecting these assets regularly can help businesses ensure that they are not degrading while not in use.
3. Predictive Maintenance (PdM)
A novel approach to improving preventative maintenance, predictive maintenance uses AI algorithms and big data analysis to forecast when maintenance will be necessary.
The algorithm uses historical asset performance data and real-time monitoring to see failure coming, allowing the asset owner to preemptively schedule maintenance in response to potential downtime. Common sources of real-time monitoring data include built-in equipment sensors, IoT monitoring devices and logging software.
Predictive maintenance can allow asset owners to minimize maintenance costs, reduce downtime and extend the lifespan of their assets.
Specific savings will vary from data center to data center, but the Department of Energy estimates that businesses can save between 8% to 12% on maintenance expenses by switching from PM to PdM. The same business would also cut downtime by 35% to 45%.
Using Preventative Maintenance in Data Centers
PM can be an invaluable tool for data center owners wanting to minimize downtime and maximize the lifespan of key assets.
Time-based PM or predictive maintenance will likely be most useful for assets that are online most of the time. Usage-based PM can be useful for assets that are used less frequently (or spend a great deal of time ideal or in storage).
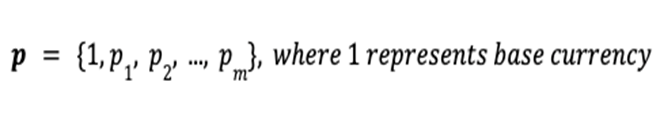
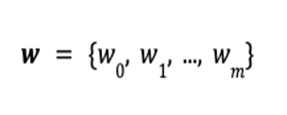
 , the total value
, the total value  of the portfolio is defined as the inner product of the price vector
of the portfolio is defined as the inner product of the price vector  and the portfolio vector
and the portfolio vector  .
. at the terminal time step
at the terminal time step  .
.
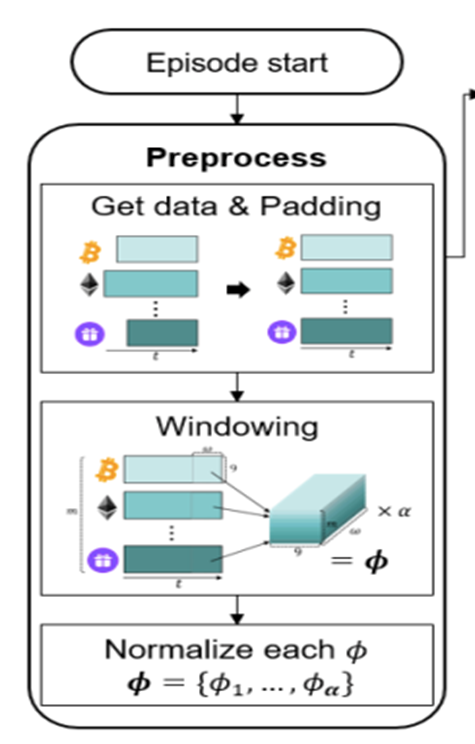
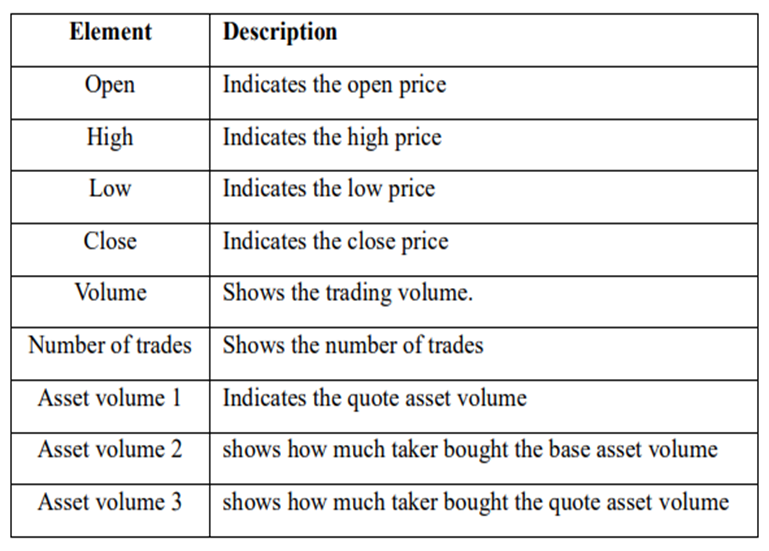

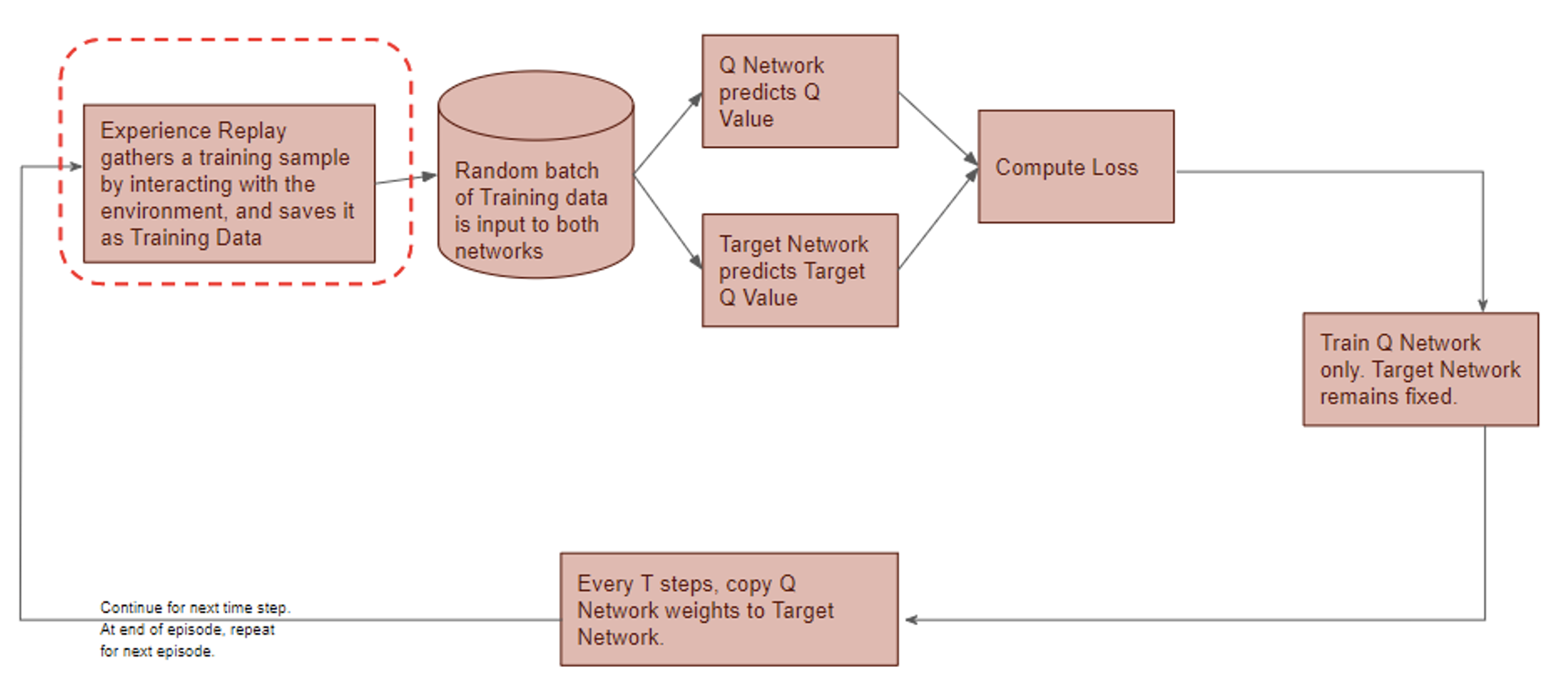
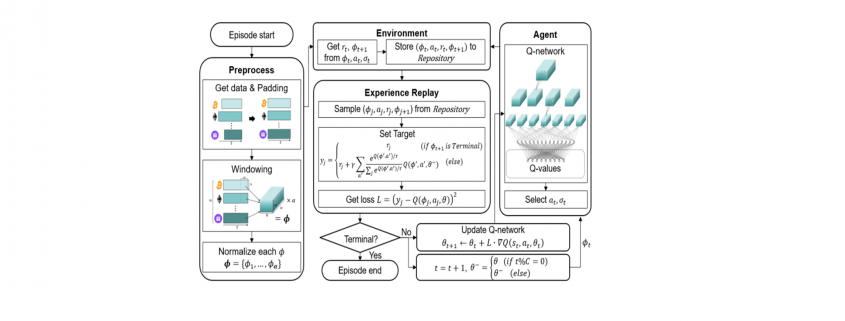
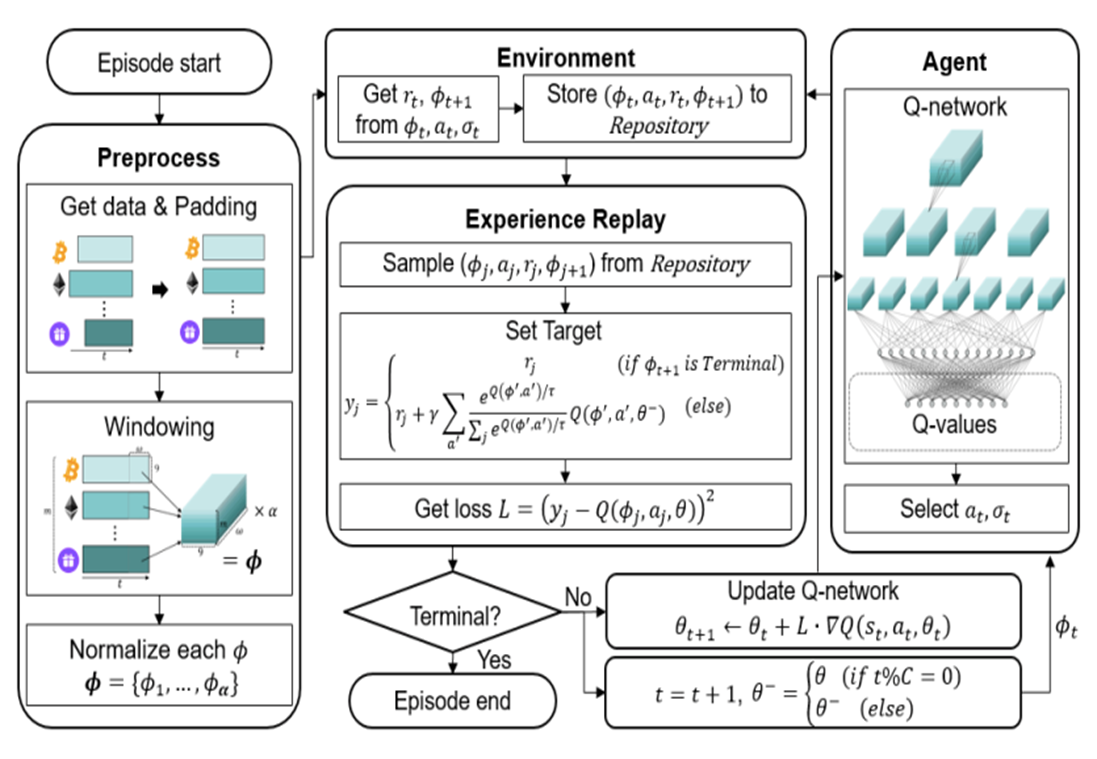
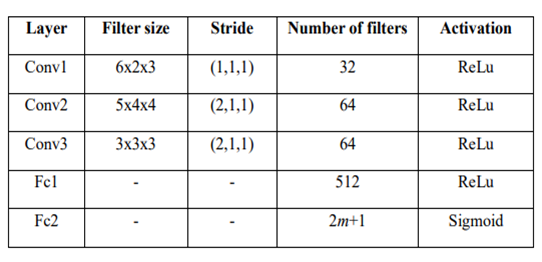
 ) is stored in the repository as a sample of training data.
) is stored in the repository as a sample of training data.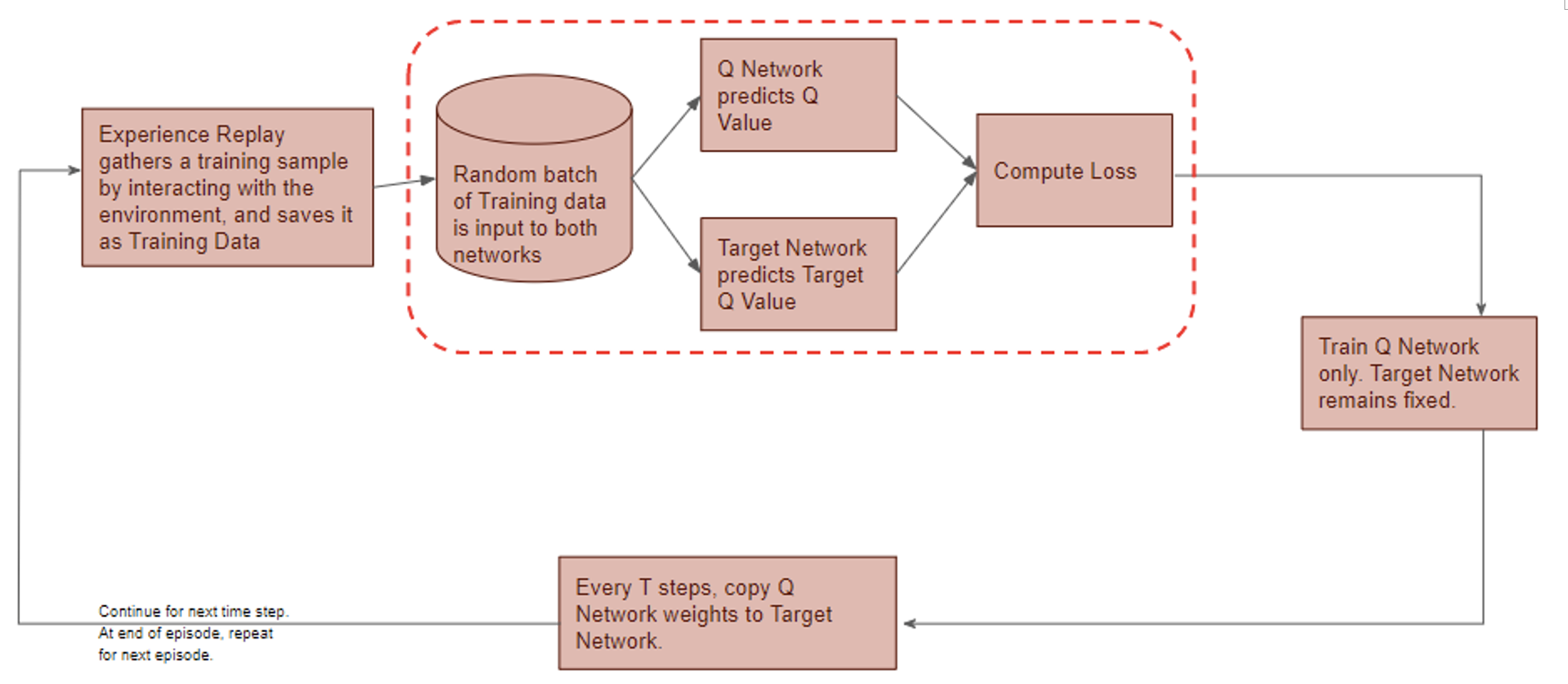
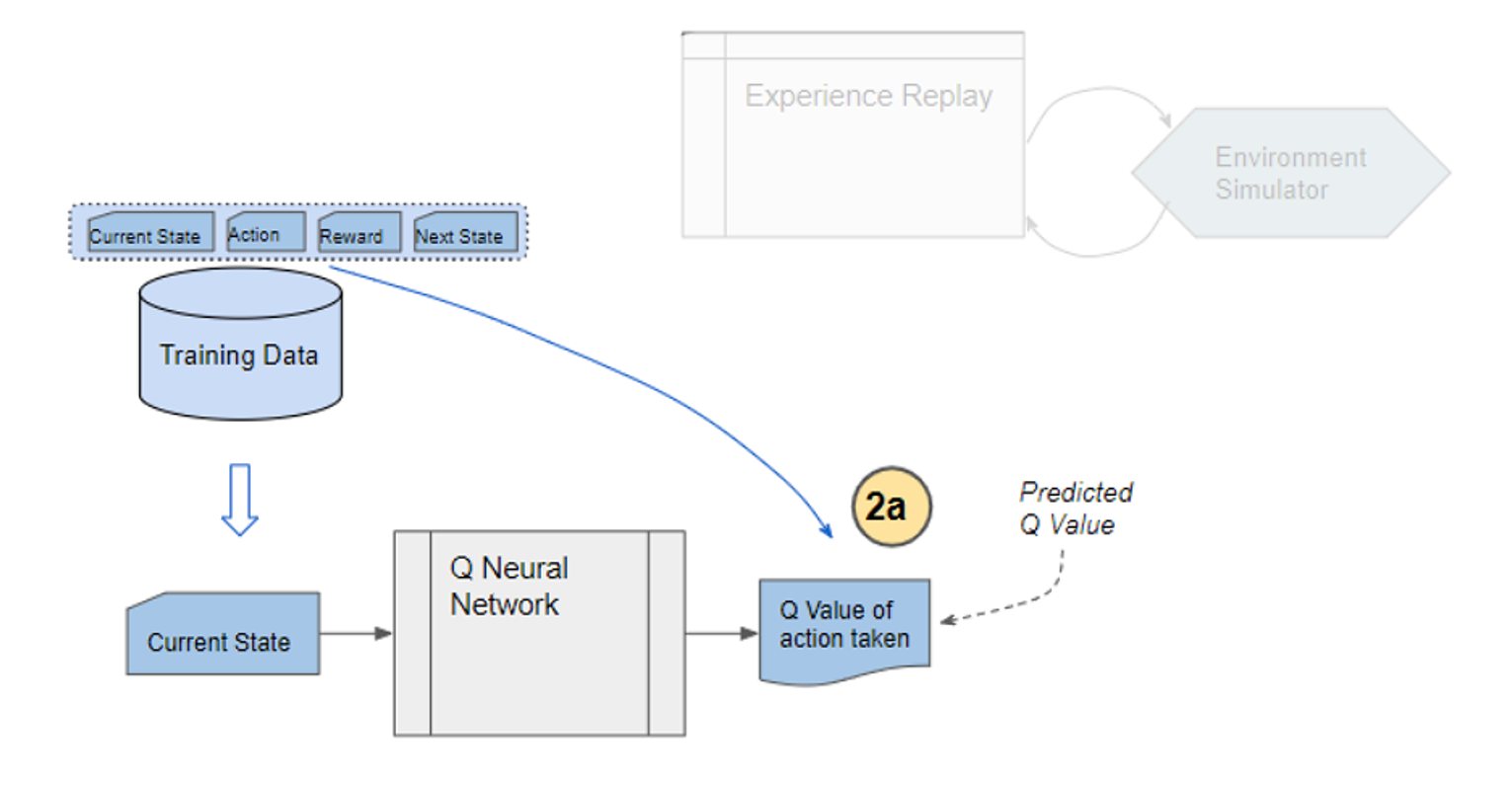
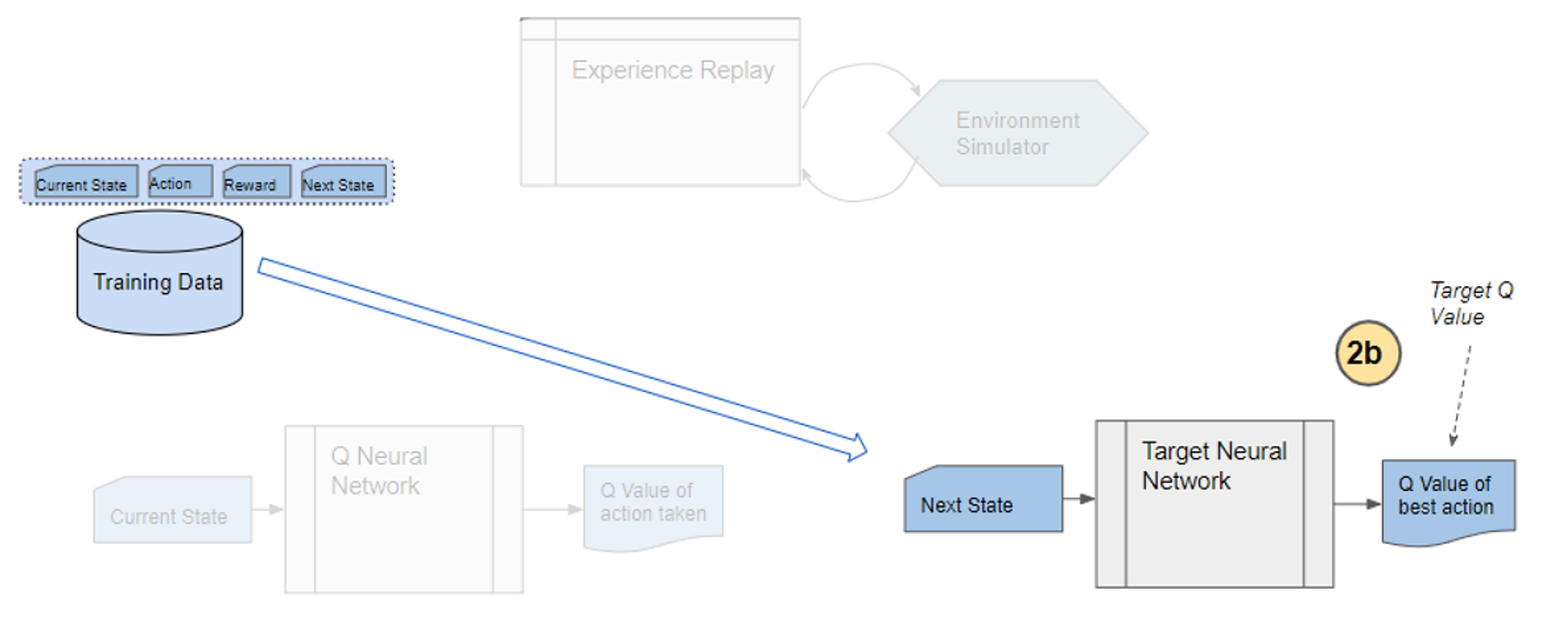
 is defined as the softmax value for the q-value of each action (ie. i-th asset at
is defined as the softmax value for the q-value of each action (ie. i-th asset at  , then i-th asset is bought using 50% of base currency).
, then i-th asset is bought using 50% of base currency).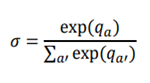
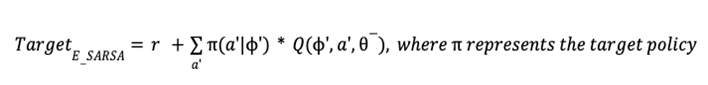
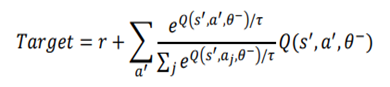
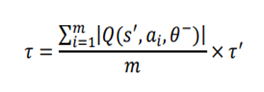
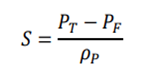
 is the return of a risk-free asset, which is set to 0 here.
is the return of a risk-free asset, which is set to 0 here.