Bag of Words: Convert text into vectors
In this blog, we will study about the model that represents and converts text to numbers i.e. the Bag of Words (BOW). The bag-of-words model has seen great success in solving problems which includes language modeling and document classification as it is simple to understand and implement.
After completing this particular blog, you all will have an overview of: What does the bag-of-words model mean by and why is its importance in representing text. How we can develop a bag-of-words model for a collection of documents. How to use the bag of words to prepare a vocabulary and deploy in a model using programming language.
The problem and its solution…
The biggest problem with modeling text is that it is unorganised, and most of the statistical algorithms, i.e., the machine learning and deep learning techniques prefer well defined numeric data. They cannot work with raw text directly, therefore we have to convert text into numbers.
Word embeddings are commonly used in many Natural Language Processing (NLP) tasks because they are found to be useful representations of words and often lead to better performance in the various tasks performed. A huge number of approaches exist in this regard, among which some of the most widely used are Bag of Words, Fasttext, TF-IDF, Glove and word2vec. For easy user implementation, several libraries exist, such as Scikit-Learn and NLTK, which can implement these techniques in one line of code. But it is important to understand the working principle behind these word embedding techniques. As already said before, in this blog, we see how to implement Bag of words and the best way to do so is to implement these techniques from scratch in Python . Before we start with coding, let’s try to understand the theory behind the model approach.
Theory Behind Bag of Words Approach
In simple words, Bag of words can be defined as a Natural Language Processing technique used for text modelling or we can say that it is a method of feature extraction with text data from documents. It involves mainly two things firstly, a vocabulary of known words and, then a measure of the presence of known words.
The process of converting NLP text into numbers is called vectorization in machine learning language.A lot of different ways are available in converting text into vectors which are:
Counting the number of times each word appears in a document, and Calculating the frequency that each word appears in a document out of all the words in the document.
Understanding using an example
To understand the bag of words approach, let’s see how this technique converts text into vectors with the help of an example. Suppose we have a corpus with three sentences:
- “I like to eat mangoes”
- “Did you like to eat jellies?”
- “I don’t like to eat jellies”
Step 1: Firstly, we go through all the words in the above three sentences and make a list of all of the words present in our model vocabulary.
- I
- like
- to
- eat
- mangoes
- Did
- you
- like
- to
- eat
- Jellies
- I
- don’t
- like
- to
- eat
- jellies
Step 2: Let’s find out the frequency of each word without preprocessing our text.
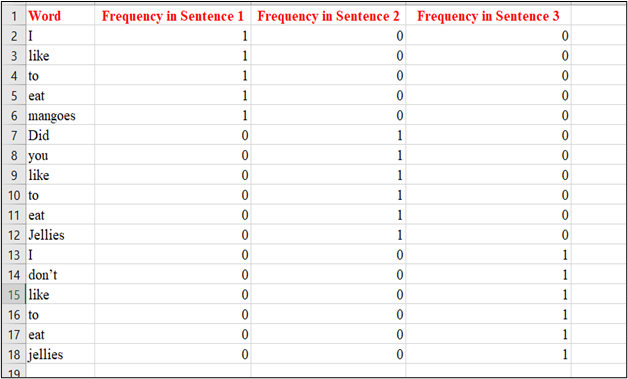
But is this not the best way to perform a bag of words. In the above example, the words Jellies and jellies are considered twice no doubt they hold the same meaning. So, let us make some changes and see how we can use ‘bag of words’ by preprocessing our text in a more effective way.
Step 3: Let’s find out the frequency of each word with preprocessing our text. Preprocessing is so very important because it brings our text into such a form that is easily understandable, predictable and analyzable for our task.
Firstly, we need to convert the above sentences into lowercase characters as case does not hold any information. Then it is very important to remove any special characters or punctuations if present in our document, or else it makes the conversion more messy.
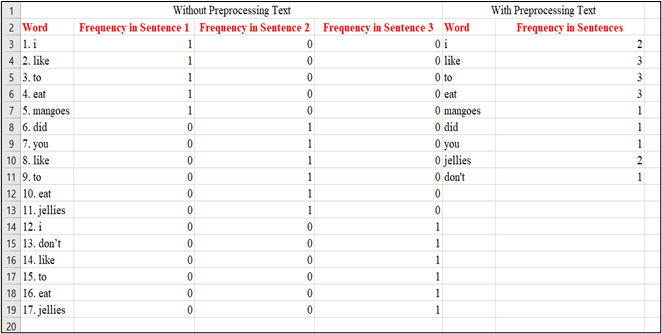
From the above explanation, we can say the major advantage of Bag of Words is that it is very easy to understand and quite simple to implement in our datasets. But this approach has some disadvantages too such as:
- Bag of words leads to a high dimensional feature vector due to the large size of word vocabulary.
- Bag of words assumes all words are independent of each other ie’, it doesn’t leverage co-occurrence statistics between words.
- It leads to a highly sparse vector as there is nonzero value in dimensions corresponding to words that occur in the sentence.
Bag of Words Model in Python Programming
The first thing that we need to create is a proper dataset for implementing our Bag of Words model. In the above sections, we have manually created a bag of words model with three sentences. However, now we shall find a random corpus on Wikipedia such as ‘https://en.wikipedia.org/wiki/Bag-of-words_model‘.
Step 1: The very first step is to import the required libraries: nltk, numpy, random, string, bs4, urllib.request and re.
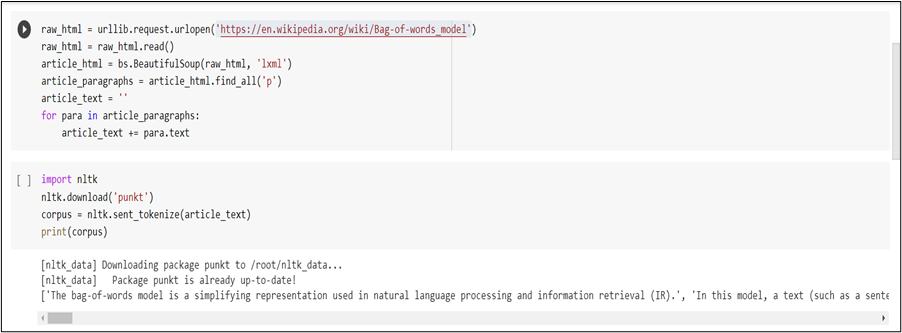
Step 2: Once we are done with importing the libraries, now we will be using the Beautifulsoup4 library to parse the data from Wikipedia.Along with that we shall be using Python’s regex library, re, for preprocessing tasks of our document. So, we will scrape the Wikipedia article on Bag of Words.

Step 3: As we can observe, in the above code snippet we have imported the raw HTML for the Wikipedia article from which we have filtered the text within the paragraph text and, finally,have created a complete corpus by merging up all the paragraphs.
Step 4: The very next step is to split the corpus into individual sentences by using the sent_tokenize function from the NLTK library.
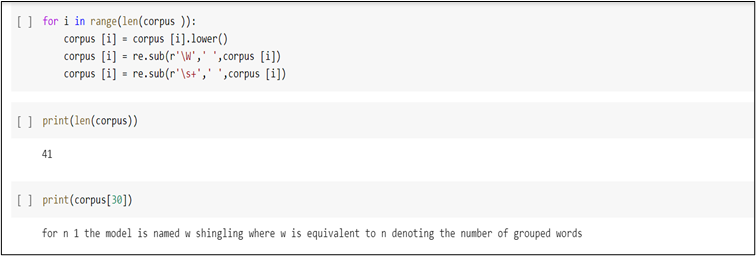
Step 5: Our text contains a number of punctuations which are unnecessary for our word frequency dictionary. In the below code snippet, we will see how to convert our text into lower case and then remove all the punctuations from our text, which will result in multiple empty spaces which can be again removed using regex.
Step 6: Once the preprocessing is done, let’s find out the number of sentences present in our corpus and then, print one sentence from our corpus to see how it looks.
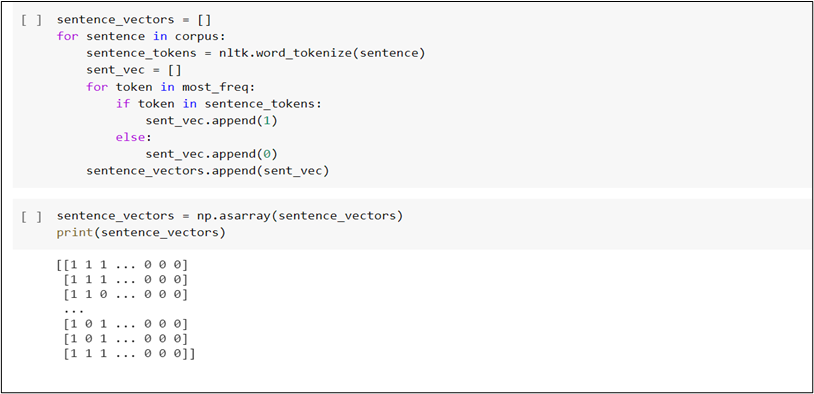
 Step 7: We can observe that the text doesn’t contain any special character or multiple empty spaces, and so our own corpus is ready. The next step is to tokenize each sentence in the corpus and create a dictionary containing each word and their corresponding frequencies.
Step 7: We can observe that the text doesn’t contain any special character or multiple empty spaces, and so our own corpus is ready. The next step is to tokenize each sentence in the corpus and create a dictionary containing each word and their corresponding frequencies.
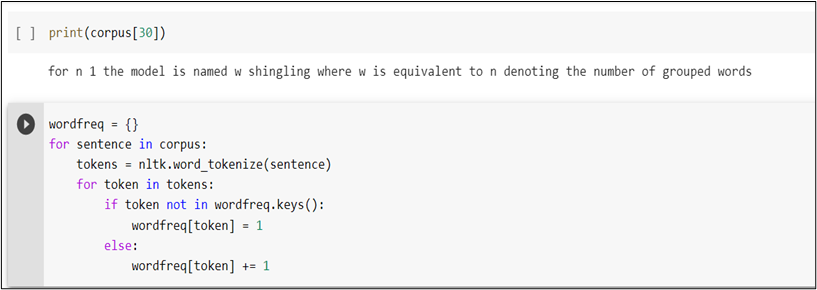
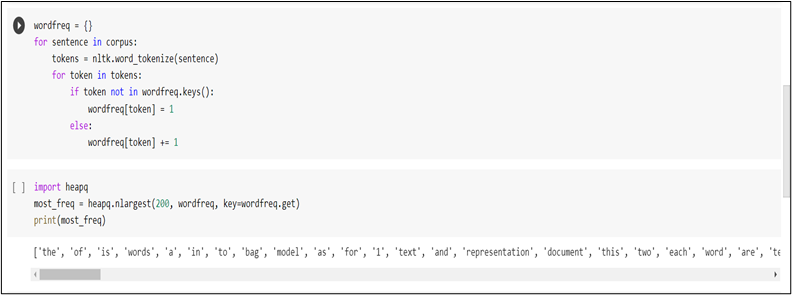
As you can see above, we have created a dictionary called wordfreq. Next, we iterate through each word in the sentence and check if it exists in the wordfreq dictionary. On its existence,we will add the word as the key and set the value of the word as 1.
Step 8: Our corpus has more than 500 words in total and so we shall filter down to the 200 most frequently occurring words by using Python’s heap library.
Step 9: Now, comes the final step of converting the sentences in our corpus into their corresponding vector representation. Let’s check the below code snippet to understand it. Our model is in the form of a list of lists which can be easily converted matrix form using this script: