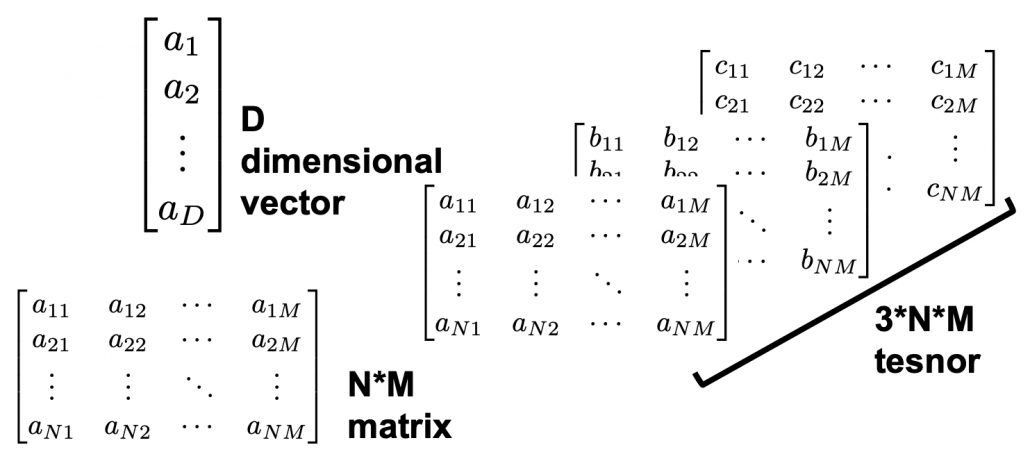
Rethinking linear algebra part two: ellipsoids in data science
1 Our expedition of eigenvectors still continues
This article is still going to be about eigenvectors and PCA, and this article still will not cover LDA (linear discriminant analysis). Hereby I would like you to have more organic links of the data science ideas with eigenvectors.
In the second article, we have covered the following points:
- You can visualize linear transformations with matrices by calculating displacement vectors, and they usually look like vectors swirling.
- Diagonalization is finding a direction in which the displacement vectors do not swirl, and that is equal to finding new axis/basis where you can describe its linear transformations more straightforwardly. But we have to consider diagonalizability of the matrices.
- In linear dimension reduction such as PCA or LDA, we mainly use types of matrices called positive definite or positive semidefinite matrices.
In the last article we have seen the following points:
- PCA is an algorithm of calculating orthogonal axes along which data “swell” the most.
- PCA is equivalent to calculating a new orthonormal basis for the data where the covariance between components is zero.
- You can reduced the dimension of the data in the new coordinate system by ignoring the axes corresponding to small eigenvalues.
- Covariance matrices enable linear transformation of rotation and expansion and contraction of vectors.
I emphasized that the axes are more important than the surface of the high dimensional ellipsoids, but in this article let’s focus more on the surface of ellipsoids, or I would rather say general quadratic curves. After also seeing how to draw ellipsoids on data, you would see the following points about PCA or eigenvectors.
- Covariance matrices are real symmetric matrices, and also they are positive semidefinite. That means you can always diagonalize covariance matrices, and their eigenvalues are all equal or greater than 0.
- PCA is equivalent to finding axes of quadratic curves in which gradients are biggest. The values of quadratic curves increases the most in those directions, and that means the directions describe great deal of information of data distribution.
- Intuitively dimension reduction by PCA is equal to fitting a high dimensional ellipsoid on data and cutting off the axes corresponding to small eigenvalues.
Even if you already understand PCA to some extent, I hope this article provides you with deeper insight into PCA, and at least after reading this article, I think you would be more or less able to visually control eigenvectors and ellipsoids with the Numpy and Maplotlib libraries.
*Let me first introduce some mathematical facts and how I denote them throughout this article in advance. If you are allergic to mathematics, take it easy or please go back to my former articles.
- Any quadratic curves can be denoted as
 , where
, where 


 .
. - When I want to clarify dimensions of variables of quadratic curves, I denote parameters as
 .
. - If a matrix
 is a real symmetric matrix, there exist a rotation matrix
is a real symmetric matrix, there exist a rotation matrix  such that
such that  , where
, where  and
and  .
.  are eigenvectors corresponding to
are eigenvectors corresponding to  respectively.
respectively. - PCA corresponds to a case of diagonalizing where is a covariance matrix of certain data. When I want to clarify that is a covariance matrix, I denote it as
 .
. - Importantly covariance matrices
 are positive semidefinite and real symmetric, which means you can always diagonalize and any of their engenvalues cannot be lower than 0.
are positive semidefinite and real symmetric, which means you can always diagonalize and any of their engenvalues cannot be lower than 0.
*In the last article, I denoted the covariance of data as  , based on Pattern Recognition and Machine Learning by C. M. Bishop.
, based on Pattern Recognition and Machine Learning by C. M. Bishop.
*Sooner or later you are going to see that I am explaining basically the same ideas from different points of view, using the topic of PCA. However I believe they are all important when you learn linear algebra for data science of machine learning. Even you have not learnt linear algebra or if you have to teach linear algebra, I recommend you to first take a review on the idea of diagonalization, like the second article. And you should be conscious that, in the context of machine learning or data science, only a very limited type of matrices are important, which I have been explaining throughout this article.
2 Rotation or projection?
In this section I am going to talk about basic stuff found in most textbooks on linear algebra. In the last article, I mentioned that if is a real symmetric matrix, you can diagonalize with a rotation matrix  , such that
, such that 

 , where
, where  . I also explained that PCA is a case where , that is, is the covariance matrix of certain data. is known to be positive semidefinite and real symmetric. Thus you can always diagonalize and any of their engenvalues cannot be lower than 0.
. I also explained that PCA is a case where , that is, is the covariance matrix of certain data. is known to be positive semidefinite and real symmetric. Thus you can always diagonalize and any of their engenvalues cannot be lower than 0.
I think we first need to clarify the difference of rotation and projection. In order to visualize the ideas, let’s consider a case of  . Assume that you have got an orthonormal rotation matrix
. Assume that you have got an orthonormal rotation matrix  which diagonalizes . In the last article I said diagonalization is equivalent to finding new orthogonal axes formed by eigenvectors, and in the case of this section you got new orthonoramal basis
which diagonalizes . In the last article I said diagonalization is equivalent to finding new orthogonal axes formed by eigenvectors, and in the case of this section you got new orthonoramal basis  which are in red in the figure below. Projecting a point
which are in red in the figure below. Projecting a point  on the new orthonormal basis is simple: you just have to multiply
on the new orthonormal basis is simple: you just have to multiply  with
with  . Let
. Let  be
be  , and then
, and then  . You can see
. You can see  are projected on
are projected on  respectively, and the left side of the figure below shows the idea. When you replace the orginal orthonormal basis
respectively, and the left side of the figure below shows the idea. When you replace the orginal orthonormal basis  with as in the right side of the figure below, you can comprehend the projection as a rotation from
with as in the right side of the figure below, you can comprehend the projection as a rotation from  to
to  by a rotation matrix .
by a rotation matrix .
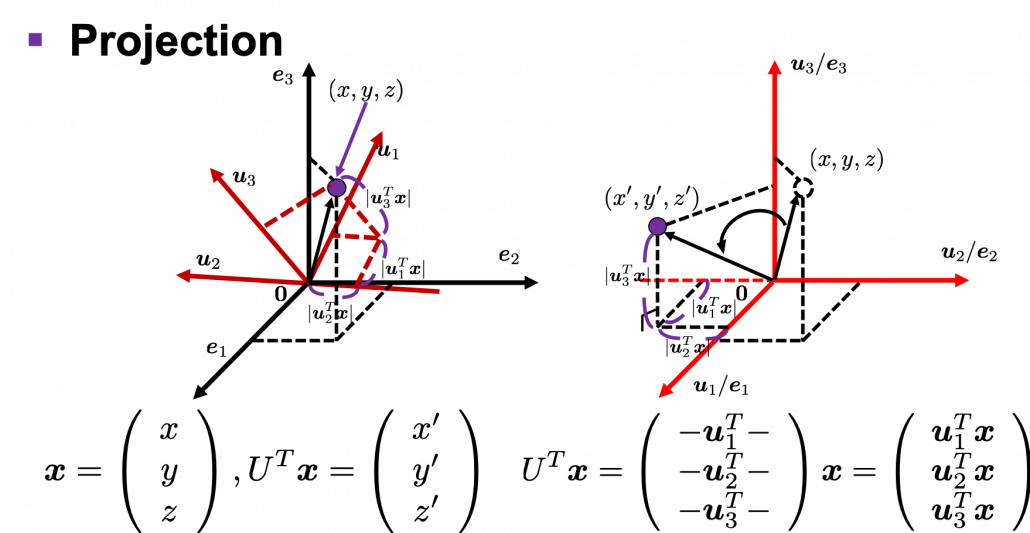
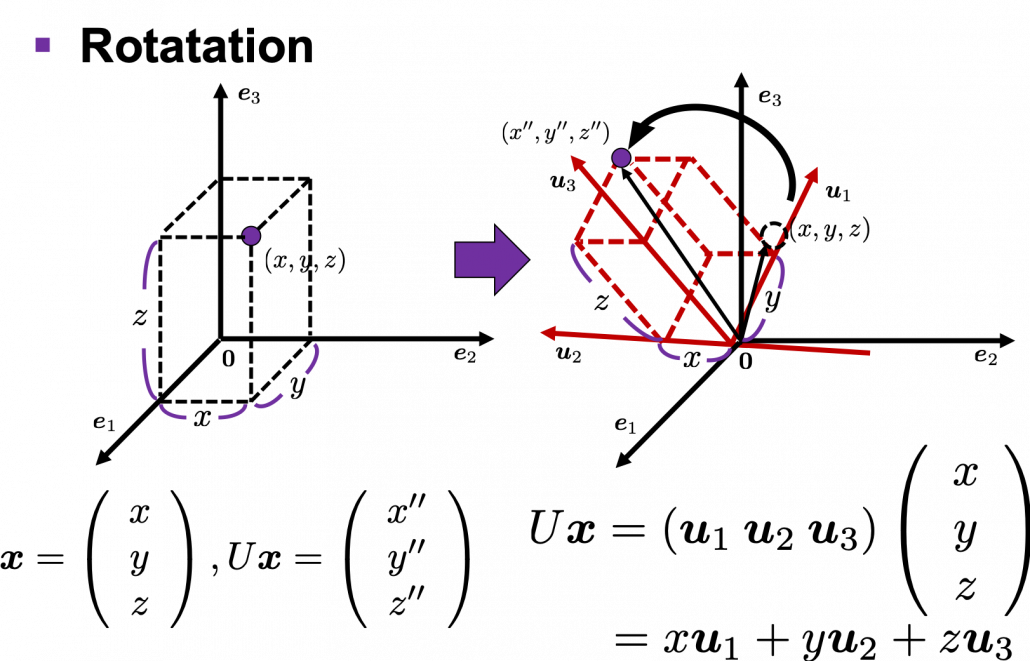
Next, let’s see what rotation is. In case of rotation, you should imagine that you rotate the point in the same coordinate system, rather than projecting to other coordinate system. You can rotate by multiplying it with . This rotation looks like the figure below.
In the initial position, the edges of the cube are aligned with the three orthogonal black axes  , with one corner of the cube located at the origin point of those axes. The purple dot denotes the corner of the cube directly opposite the origin corner. The cube is rotated in three dimensions, with the origin corner staying fixed in place. After the rotation with a pivot at the origin, the edges of the cube are now aligned with a new set of orthogonal axes
, with one corner of the cube located at the origin point of those axes. The purple dot denotes the corner of the cube directly opposite the origin corner. The cube is rotated in three dimensions, with the origin corner staying fixed in place. After the rotation with a pivot at the origin, the edges of the cube are now aligned with a new set of orthogonal axes  , shown in red. You might understand that more clearly with an equation:
, shown in red. You might understand that more clearly with an equation: 
 . In short this rotation means you keep relative position of , I mean its coordinates , in the new orthonormal basis. In this article, let me call this a “cube rotation.”
. In short this rotation means you keep relative position of , I mean its coordinates , in the new orthonormal basis. In this article, let me call this a “cube rotation.”
The discussion above can be generalized to spaces with dimensions higher than 3. When  is an orthonormal matrix and a vector
is an orthonormal matrix and a vector  , you can project to
, you can project to  or rotate it to
or rotate it to  , where
, where  and
and  . In other words
. In other words  , which means you can rotate back
, which means you can rotate back  to the original point with the rotation matrix .
to the original point with the rotation matrix .
I think you at least saw that rotation and projection are basically the same, and that is only a matter of how you look at the coordinate systems. But I would say the idea of projection is more important through out this article.
Let’s consider a function  , where
, where  is a real symmetric matrix. The distribution of
is a real symmetric matrix. The distribution of  is quadratic curves whose center point covers the origin, and it is known that you can express this distribution in a much simpler way using eigenvectors. When you project this function on eigenvectors of , that is when you substitute
is quadratic curves whose center point covers the origin, and it is known that you can express this distribution in a much simpler way using eigenvectors. When you project this function on eigenvectors of , that is when you substitute  for , you get
for , you get 



 . You can always diagonalize real symmetric matrices, so the formula implies that the shapes of quadratic curves largely depend on eigenvectors. We are going to see this in detail in the next section.
. You can always diagonalize real symmetric matrices, so the formula implies that the shapes of quadratic curves largely depend on eigenvectors. We are going to see this in detail in the next section.
* denotes an inner product of and
denotes an inner product of and  .
.
*We are going to see details of the shapes of quadratic “curves” or “functions” in the next section.
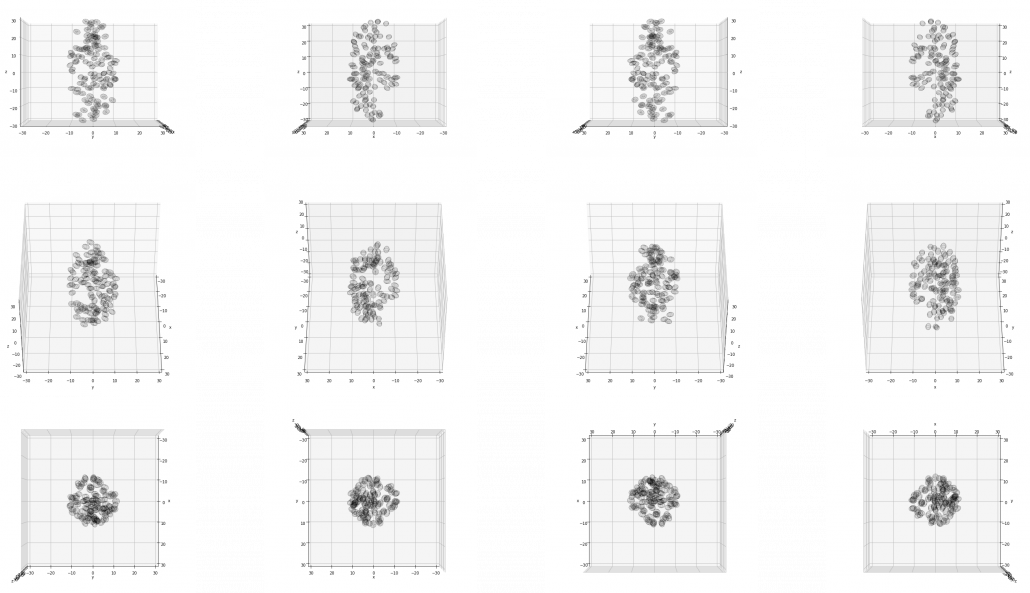
To be exact, you cannot naively multiply or for rotation. Let’s take a part of data I showed in the last article as an example. In the figure below, I projected data on the basis .
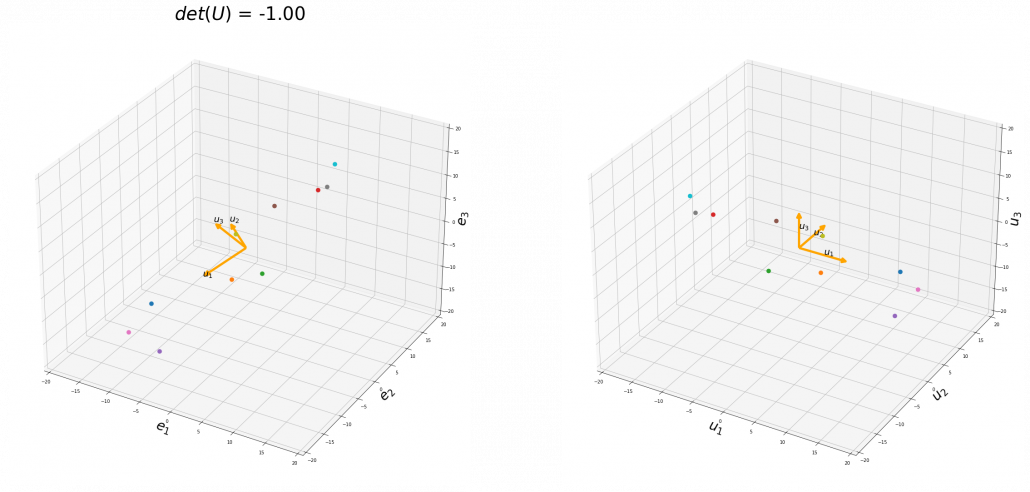
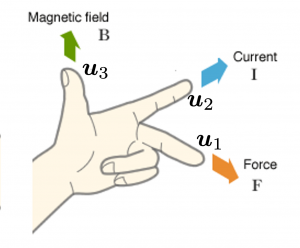
You might have noticed that you cannot do a “cube rotation” in this case. If you make the coordinate system with your left hand, like you might have done in science classes in school to learn Fleming’s rule, you would soon realize that the coordinate systems in the figure above do not match. You need to flip the direction of one axis to match them.
Mathematically, you have to consider the determinant of the rotation matrix . You can do a “cube rotation” when  , and in the case above
, and in the case above  was
was  , and you needed to flip one axis to make the determinant
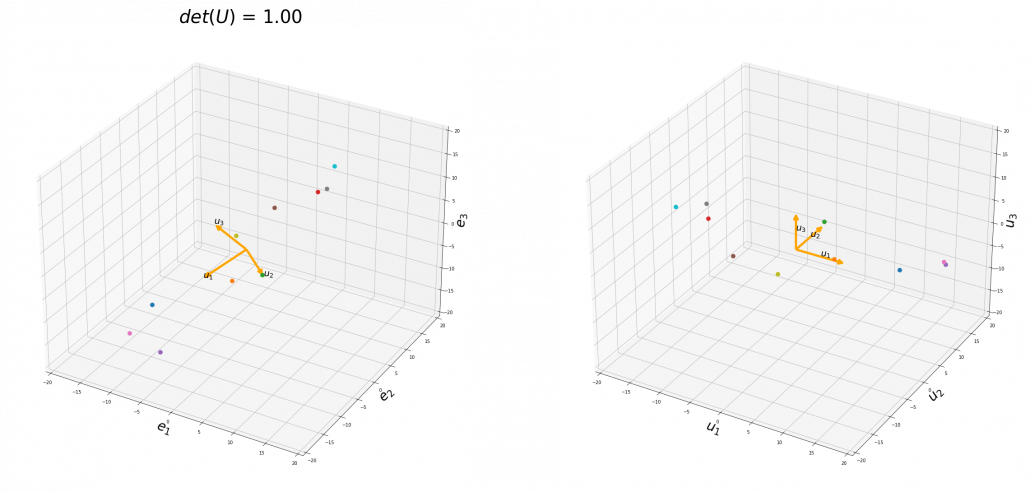
, and you needed to flip one axis to make the determinant  . In the example in the figure below, you can match the basis. This also can be generalized to higher dimensions, but that is also beyond the scope of this article series. If you are really interested, you should prepare some coffee and snacks and textbooks on linear algebra, and some weekends.
. In the example in the figure below, you can match the basis. This also can be generalized to higher dimensions, but that is also beyond the scope of this article series. If you are really interested, you should prepare some coffee and snacks and textbooks on linear algebra, and some weekends.
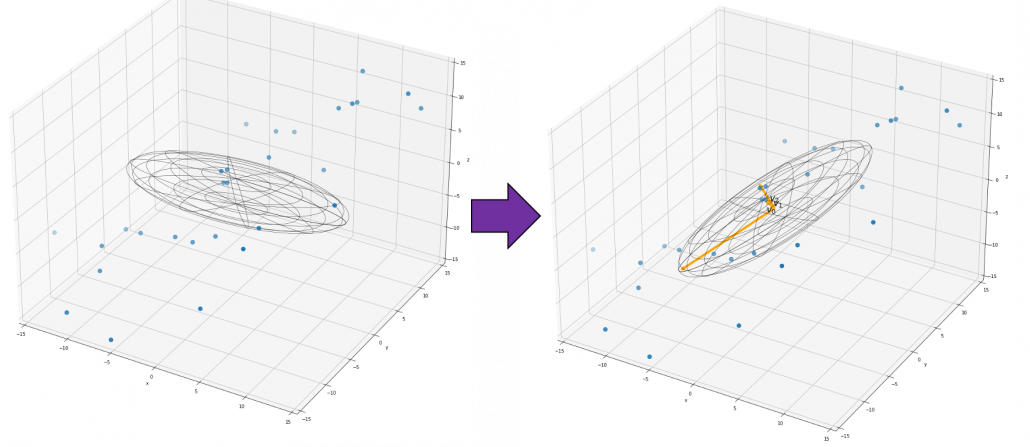
When you want to make general ellipsoids in a 3d space on Matplotlib, you can take advantage of rotation matrices. You first make a simple ellipsoid symmetric about xyz axis using polar coordinates, and you can rotate the whole ellipsoid with rotation matrices. I made some simple modules for drawing ellipsoid. If you put in a rotation matrix which diagonalize the covariance matrix of data and a list of three radiuses  , you can rotate the original ellipsoid so that it fits the data well.
, you can rotate the original ellipsoid so that it fits the data well.
3 Types of quadratic curves.
*This article might look like a mathematical writing, but I would say this is more about computer science. Please tolerate some inaccuracy in terms of mathematics. I gave priority to visualizing necessary mathematical ideas in my article series. If you are not sure about details, please let me know.
In linear dimension reduction, or at least in this article series you mainly have to consider ellipsoids. However ellipsoids are just one type of quadratic curves. In the last article, I mentioned that when the center of a D dimensional ellipsoid is the origin point of a normal coordinate system, the formula of the surface of the ellipsoid is as follows:  , where satisfies certain conditions. To be concrete, when is the surface of a ellipsoid, has to be diagonalizable and positive definite.
, where satisfies certain conditions. To be concrete, when is the surface of a ellipsoid, has to be diagonalizable and positive definite.
*Real symmetric matrices are diagonalizable, and positive definite matrices have only positive eigenvalues. Covariance matrices , whose displacement vectors I visualized in the last two articles, are known to be symmetric real matrices and positive semi-defintie. However, the surface of an ellipsoid which fit the data is  , not
, not  .
.
*You have to keep it in mind that are all deviations.
*You do not have to think too much about what the “semi” of the term “positive semi-definite” means fow now.
As you could imagine, this is just one simple case of richer variety of graphs. Let’s consider a 3-dimensional space. Any quadratic curves in this space can be denoted as  , where at least one of
, where at least one of  is not
is not  . Let be
. Let be  , then the quadratic curves can be simply denoted with a
, then the quadratic curves can be simply denoted with a  matrix and a 3-dimensional vector
matrix and a 3-dimensional vector  as follows: , where
as follows: , where  ,
,  . General quadratic curves are roughly classified into the 9 types below.
. General quadratic curves are roughly classified into the 9 types below.

You can shift these quadratic curves so that their center points come to the origin, without rotation, and the resulting curves are as follows. The curves can be all denoted as  .
.
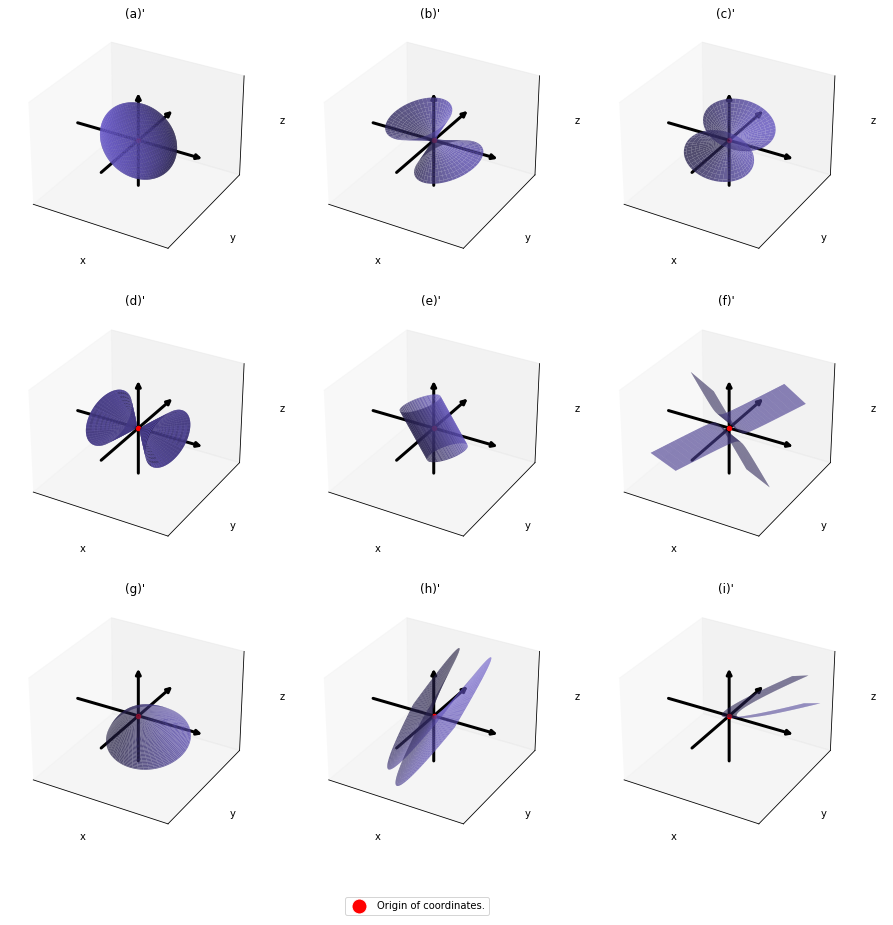
As you can see, is a real symmetric matrix. As I have mentioned repeatedly, when all the elements of a  symmetric matrix are real values and its eigen values are
symmetric matrix are real values and its eigen values are  , there exist orthogonal/orthonormal matrices such that
, there exist orthogonal/orthonormal matrices such that  , where . Hence, you can diagonalize the with an orthogonal matrix . Let be an orthogonal matrix such that
, where . Hence, you can diagonalize the with an orthogonal matrix . Let be an orthogonal matrix such that 
 . After you apply rotation by to the curves (a)” ~ (i)”, those curves are symmetrically placed about the xyz axes, and their center points still cross the origin. The resulting curves look like below. Or rather I should say you projected (a)’ ~ (i)’ on their eigenvectors.
. After you apply rotation by to the curves (a)” ~ (i)”, those curves are symmetrically placed about the xyz axes, and their center points still cross the origin. The resulting curves look like below. Or rather I should say you projected (a)’ ~ (i)’ on their eigenvectors.
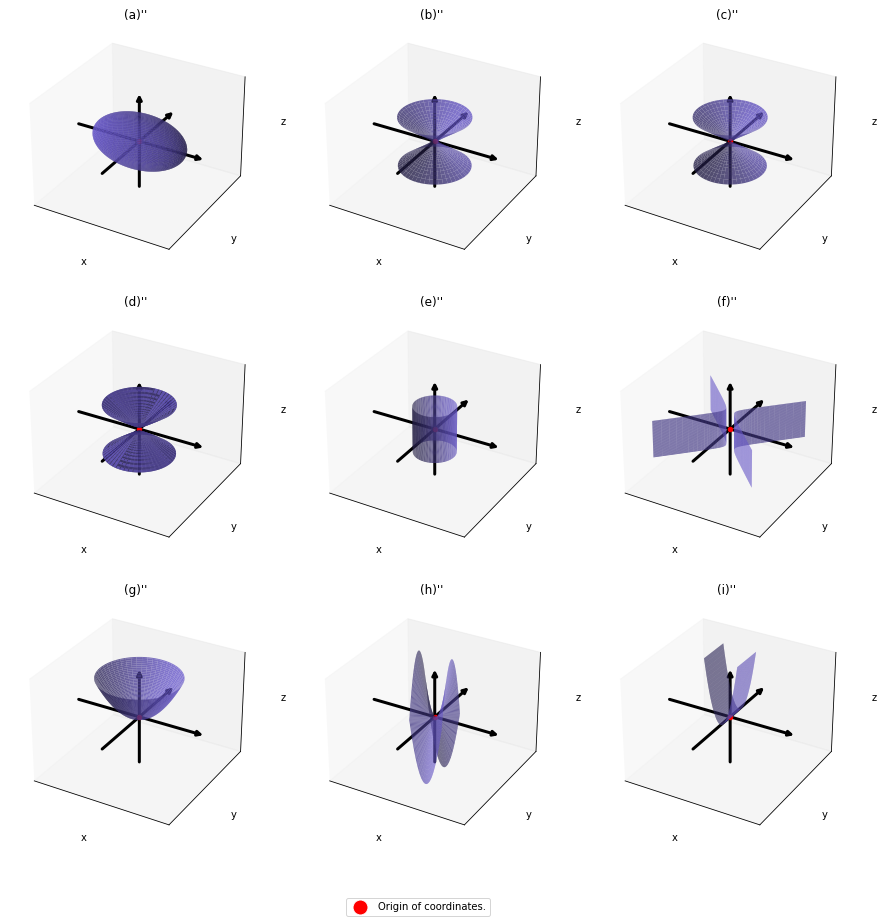
In this article mainly (a)” , (g)”, (h)”, and (i)” are important. General equations for the curves is as follows
- (a)”:

- (g)”:

- (h)”:

- (i)”:

, where  .
.
Even if this section has been puzzling to you, you just have to keep one point in your mind: we have been discussing general quadratic curves, but in PCA, you only need to consider a case where is a covariance matrix, that is . PCA corresponds to the case where you shift and rotate the curve (a) into (a)”. Subtracting the mean of data from each point of data corresponds to shifting quadratic curve (a) to (a)’. Calculating eigenvectors of corresponds to calculating a rotation matrix such that the curve (a)’ comes to (a)” after applying the rotation, or projecting curves on eigenvectors of . Importantly we are only discussing the covariance of certain data, not the distribution of the data itself.
*Just in case you are interested in a little more mathematical sides: it is known that if you rotate all the points on the curve with the rotation matrix  , those points are mapped into a new quadratic curve
, those points are mapped into a new quadratic curve  . That means the rotation of the original quadratic curve with (or rather rotating axes) enables getting rid of the terms
. That means the rotation of the original quadratic curve with (or rather rotating axes) enables getting rid of the terms  . Also it is known that when
. Also it is known that when  , with proper translations and rotations, the quadratic curve can be mapped into one of the types of quadratic curves in the figure below, depending on coefficients of the original quadratic curve. And the discussion so far can be generalized to higher dimensional spaces, but that is beyond the scope of this article series. Please consult decent textbooks on linear algebra around you for further details.
, with proper translations and rotations, the quadratic curve can be mapped into one of the types of quadratic curves in the figure below, depending on coefficients of the original quadratic curve. And the discussion so far can be generalized to higher dimensional spaces, but that is beyond the scope of this article series. Please consult decent textbooks on linear algebra around you for further details.
4 Eigenvectors are gradients and sometimes variances.
In the second section I explained that you can express quadratic functions  in a very simple way by projecting on eigenvectors of .
in a very simple way by projecting on eigenvectors of .
You can comprehend what I have explained in another way: eigenvectors, to be exact eigenvectors of real symmetric matrices , are gradients. And in case of PCA, I mean when eigenvalues are also variances. Before explaining what that means, let me explain a little of the totally common facts on mathematics. If you have variables , I think you can comprehend functions  in two ways. One is a normal “functions”
in two ways. One is a normal “functions”  , and the others are “curves”
, and the others are “curves”  . “Functions” get an input and gives out an output , just as well as normal functions you would imagine. “Curves” are rather sets of such that .
. “Functions” get an input and gives out an output , just as well as normal functions you would imagine. “Curves” are rather sets of such that .
*Please assume that the terms “functions” and “curves” are my original words. I use them just in case I fail to use functions and curves properly.
The quadratic curves in the figure above are all “curves” in my term, which can be denoted as  or
or  . However if you replace
. However if you replace  of (g)”, (h)”, and (i)” with
of (g)”, (h)”, and (i)” with  , you can interpret the “curves” as “functions” which are denoted as
, you can interpret the “curves” as “functions” which are denoted as  . This might sounds too obvious to you, and my point is you can visualize how values of “functions” change only when the inputs are 2 dimensional.
. This might sounds too obvious to you, and my point is you can visualize how values of “functions” change only when the inputs are 2 dimensional.
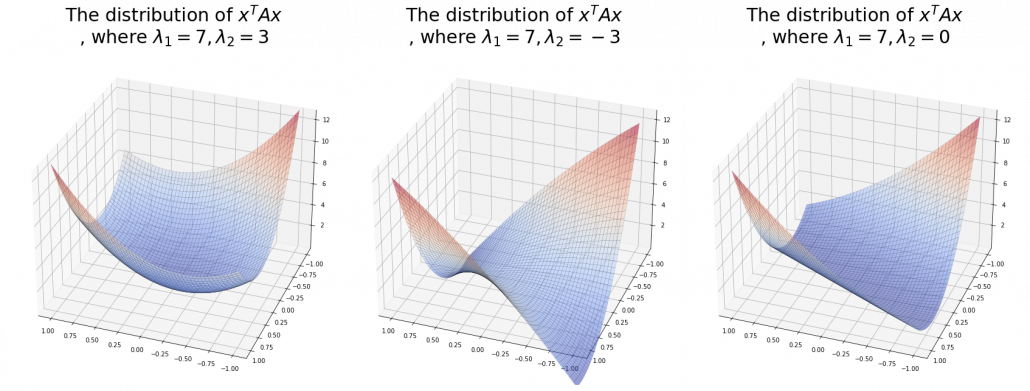
When a symmetric  real matrices
real matrices  have two eigenvalues
have two eigenvalues  , the distribution of quadratic curves can be roughly classified to the following three types.
, the distribution of quadratic curves can be roughly classified to the following three types.
- (g): Both
 and
and  are positive or negative.
are positive or negative. - (h): Either of or is positive and the other is negative.
- (i): Either of or is 0 and the other is not.
The equations of (g)” , (h)”, and (i)” correspond to each type of  , and thier curves look like the three graphs below.
, and thier curves look like the three graphs below.
And in fact, when start from the origin and go in the direction of an eigenvector  ,
,  is the gradient of the direction. You can see that more clearly when you restrict the distribution of to a unit circle. Like in the figure below, in case
is the gradient of the direction. You can see that more clearly when you restrict the distribution of to a unit circle. Like in the figure below, in case  , which is classified to (g), the distribution looks like the left side, and if you restrict the distribution in the unit circle, the distribution looks like a bowl like the middle and the right side. When you move in the direction of
, which is classified to (g), the distribution looks like the left side, and if you restrict the distribution in the unit circle, the distribution looks like a bowl like the middle and the right side. When you move in the direction of  , you can climb the bowl as as high as , in
, you can climb the bowl as as high as , in  as high as .
as high as .
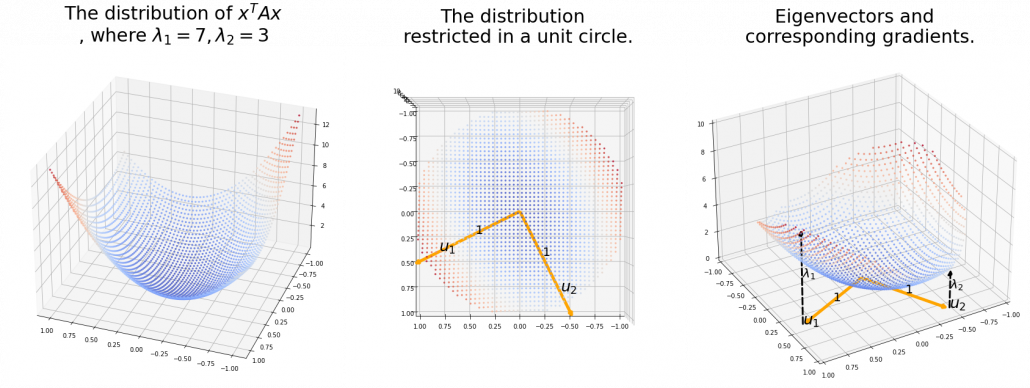
Also in case of (h), the same facts hold. But in this case, you can also descend the curve.
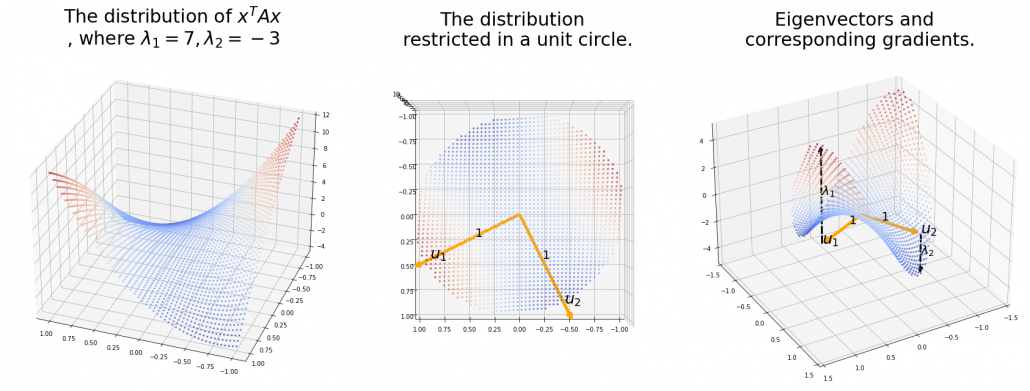
*You might have seen the curve above in the context of optimization with stochastic gradient descent. The origin of the curve above is a notorious saddle point, where gradients are all in any directions but not a local maximum or minimum. Points can be stuck in this point during optimization.
Especially in case of PCA, is a covariance matrix, thus . Eigenvalues of are all equal to or greater than . And it is known that in this case is the variance of data projected on its corresponding eigenvector  . Hence, if you project
. Hence, if you project  , quadratic curves formed by a covariance matrix , on eigenvectors of , you get
, quadratic curves formed by a covariance matrix , on eigenvectors of , you get 
 . This shows that you can re-weight
. This shows that you can re-weight  , the coordinates of data projected projected on eigenvectors of , with , which are variances . As I mentioned in an example of data of exam scores in the last article, the bigger a variance is, the more the feature described by vary from sample to sample. In other words, you can ignore eigenvectors corresponding to small eigenvalues.
, the coordinates of data projected projected on eigenvectors of , with , which are variances . As I mentioned in an example of data of exam scores in the last article, the bigger a variance is, the more the feature described by vary from sample to sample. In other words, you can ignore eigenvectors corresponding to small eigenvalues.
That is a great hint why principal components corresponding to large eigenvectors contain much information of the data distribution. And you can also interpret PCA as a “climbing” a bowl of  , as I have visualized in the case of (g) type curve in the figure above.
, as I have visualized in the case of (g) type curve in the figure above.
*But as I have repeatedly mentioned, ellipsoid which fit data well is

 .
.
*You have to be careful that even if you slice a type (h) curve with a place  the resulting cross section does not fit the original data well because the equation of the cross section is
the resulting cross section does not fit the original data well because the equation of the cross section is  The figure below is an example of slicing the same as the one above with
The figure below is an example of slicing the same as the one above with  , and the resulting cross section.
, and the resulting cross section.
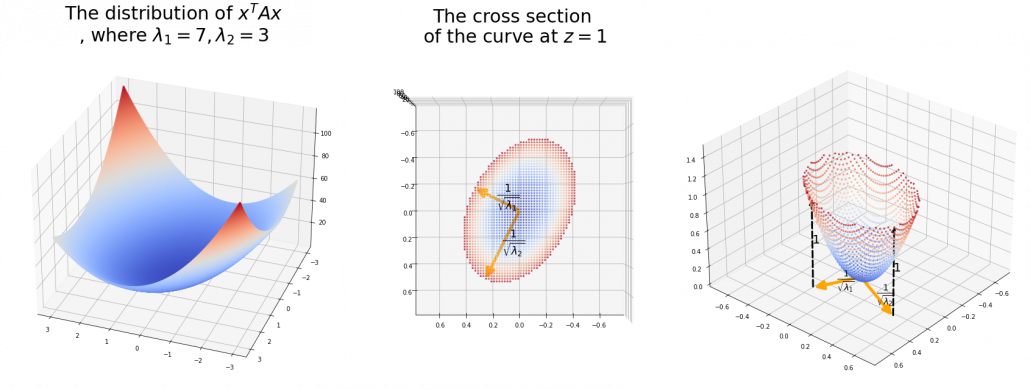
As we have seen, , the eigenvalues of the covariance matrix of data are variances or data when projected on it eigenvectors. At the same time, when you fit an ellipsoid on the data,  is the radius of the ellipsoid corresponding to . Thus ignoring data projected on eigenvectors corresponding to small eigenvalues is equivalent to cutting of the axes of the ellipsoid with small radiusses.
is the radius of the ellipsoid corresponding to . Thus ignoring data projected on eigenvectors corresponding to small eigenvalues is equivalent to cutting of the axes of the ellipsoid with small radiusses.
I have explained PCA in three different ways over three articles.
- The second article: I focused on what kind of linear transformations convariance matrices enable, by visualizing displacement vectors. And those vectors look like swirling and extending into directions of eigenvectors of .
- The third article: We directly found directions where certain data distribution “swell” the most, to find that data swell the most in directions of eigenvectors.
- In this article, we have seen PCA corresponds to only one case of quadratic functions, where the matrix is a covariance matrix. When you go in the directions of eigenvectors corresponding to big eigenvalues, the quadratic function increases the most. Also that means data samples have bigger variances when projected on the eigenvectors. Thus you can cut off eigenvectors corresponding to small eigenvectors because they retain little information about data, and that is equivalent to fitting an ellipsoid on data and cutting off axes with small radiuses.
*Let be a covariance matrix, and you can diagonalize it with an orthogonal matrix as follow:  , where . Thus
, where . Thus  . is a rotation, and multiplying a with
. is a rotation, and multiplying a with  means you multiply each eigenvalue to each element of . At the end enables the reverse rotation.
means you multiply each eigenvalue to each element of . At the end enables the reverse rotation.
If you get data like the left side of the figure below, most explanation on PCA would just fit an oval on this data distribution. However after reading this articles series so far, you would have learned to see PCA from different viewpoints like at the right side of the figure below.
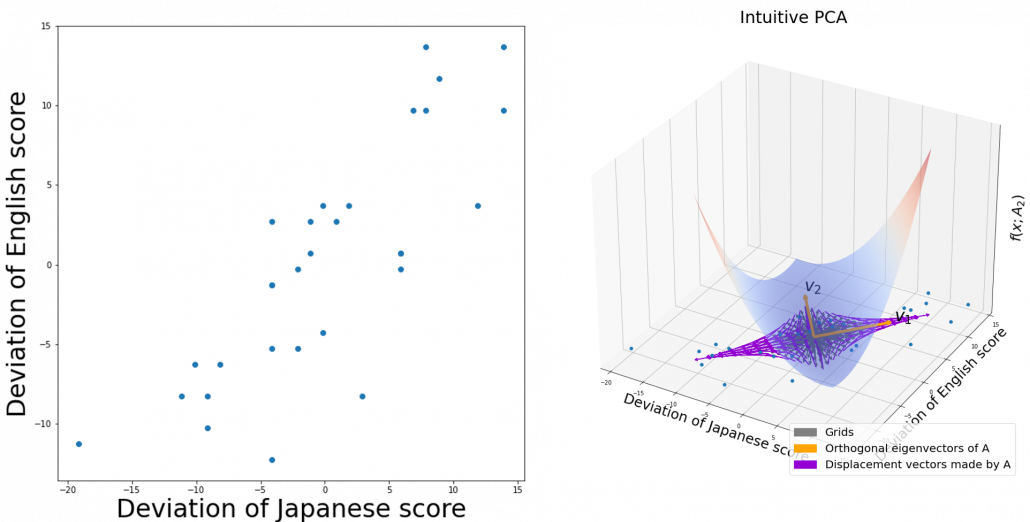
5 Ellipsoids in Gaussian distributions.
I have explained that if the covariance of a data distribution is  , the ellipsoid which fits the distribution the best is
, the ellipsoid which fits the distribution the best is  . You might have seen the part
. You might have seen the part 
 somewhere else. It is the exponent of general Gaussian distributions:
somewhere else. It is the exponent of general Gaussian distributions: 
 . It is known that the eigenvalues of
. It is known that the eigenvalues of  are
are  , and eigenvectors corresponding to each eigenvalue are also
, and eigenvectors corresponding to each eigenvalue are also  respectively. Hence just as well as what we have seen, if you project
respectively. Hence just as well as what we have seen, if you project  on each eigenvector of , we can convert the exponent of the Gaussian distribution.
on each eigenvector of , we can convert the exponent of the Gaussian distribution.
Let  be and
be and  be
be  , where
, where  . Just as we have seen,
. Just as we have seen, 



 . Hence
. Hence 
 .
.
*To be mathematically exact about changing variants of normal distributions, you have to consider for example Jacobian matrices.
This results above demonstrate that, by projecting data on the eigenvectors of its covariance matrix, you can factorize the original multi-dimensional Gaussian distribution into a product of Gaussian distributions which are irrelevant to each other. However, at the same time, that is the potential limit of approximating data with PCA. This idea is going to be more important when you think about more probabilistic ways to handle PCA, which is more robust to lack of data.
I have explained PCA over 3 articles from various viewpoints. If you have been patient enough to read my article series, I think you have gained some deeper insight into not only PCA, but also linear algebra, and that should be helpful when you learn or teach data science. I hope my codes also help you. In fact these are not the only topics about PCA. There are a lot of important PCA-like algorithms.
In fact our expedition of ellipsoids, or PCA still continues, just as Star Wars series still continues. Especially if I have to explain an algorithm named probabilistic PCA, I need to explain the “Bayesian world” of machine learning. Most machine learning algorithms covered by major introductory textbooks tend to be too deterministic and dependent on the size of data. Many of those algorithms have another “parallel world,” where you can handle inaccuracy in better ways. I hope I can also write about them, and I might prepare another trilogy for such PCA. But I will not disappoint you, like “The Phantom Menace.”
Appendix: making a model of a bunch of grape with ellipsoid berries.
If you can control quadratic curves, reshaping and rotating them, you can make a model of a grape of olive bunch on Matplotlib. I made a program of making a model of a bunch of berries on Matplotlib using the module to draw ellipsoids which I introduced earlier. You can check the codes in this page.
*I have no idea how many people on this earth are in need of making such models.
I made some modules so that you can see the grape bunch from several angles. This might look very simple to you, but the locations of berries are organized carefully so that it looks like they are placed around a stem and that the berries are not too close to each other.
The programming code I created for this article is completly available here.
[Refereces]
[1]C. M. Bishop, “Pattern Recognition and Machine Learning,” (2006), Springer, pp. 78-83, 559-577
[2]「理工系新課程 線形代数 基礎から応用まで」, 培風館、(2017)
[3]「これなら分かる 最適化数学 基礎原理から計算手法まで」, 金谷健一著、共立出版, (2019), pp. 17-49
[4]「これなら分かる 応用数学教室 最小二乗法からウェーブレットまで」, 金谷健一著、共立出版, (2019), pp.165-208
[5] 「サボテンパイソン 」
https://sabopy.com/

 be a vector space and let
be a vector space and let  be a mapping of
be a mapping of  into itself, defined as
into itself, defined as  , where
, where  matrix and
matrix and  is
is  dimensional vector. An element
dimensional vector. An element  is called an eigen vector if there exists a number
is called an eigen vector if there exists a number  such that
such that  and
and  . In this case
. In this case  , belonging to
, belonging to  . If
. If  is basis of the vector space
is basis of the vector space  , whose column vectors are eigen vectors
, whose column vectors are eigen vectors  , where
, where  .
. Most textbooks keep explaining these type of stuff, but I have to say they lack efforts to make it understandable to readers with low mathematical literacy like me. Especially if you have to apply the idea to data science field, I believe you need more visual understanding of diagonalization. Therefore instead of just explaining the definitions and theorems, I would like to take a different approach. But in order to understand them in more intuitive ways, we first have to rethink waht linear transformation
Most textbooks keep explaining these type of stuff, but I have to say they lack efforts to make it understandable to readers with low mathematical literacy like me. Especially if you have to apply the idea to data science field, I believe you need more visual understanding of diagonalization. Therefore instead of just explaining the definitions and theorems, I would like to take a different approach. But in order to understand them in more intuitive ways, we first have to rethink waht linear transformation  means in more visible ways.
means in more visible ways. is a vector transformed by
is a vector transformed by  *I am not going to use the term “linear transformation” in a precise way in the context of linear algebra. In this article or in the context of data science or machine learning, “linear transformation” for the most part means products of matrices or vectors.
*I am not going to use the term “linear transformation” in a precise way in the context of linear algebra. In this article or in the context of data science or machine learning, “linear transformation” for the most part means products of matrices or vectors. 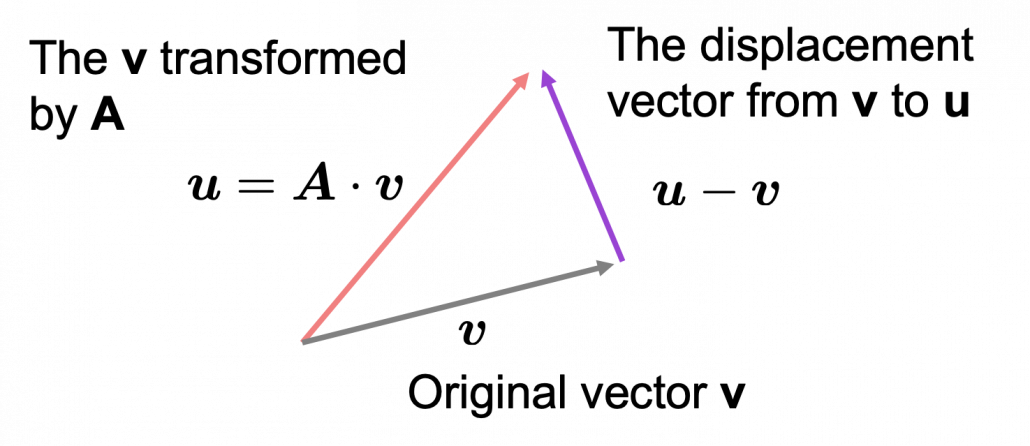 Let’s calculate the displacement vector with more vectors
Let’s calculate the displacement vector with more vectors  , and I prepared several grid vectors
, and I prepared several grid vectors  in purple.
in purple. square matrices
square matrices  , and I plotted displace vectors made by the matrices respectively in the figure below.
, and I plotted displace vectors made by the matrices respectively in the figure below. , the matrix does not have any real eigan values.
, the matrix does not have any real eigan values. is classified to, and I am going to explain positive semidefinite matrices in the fourth section.
is classified to, and I am going to explain positive semidefinite matrices in the fourth section.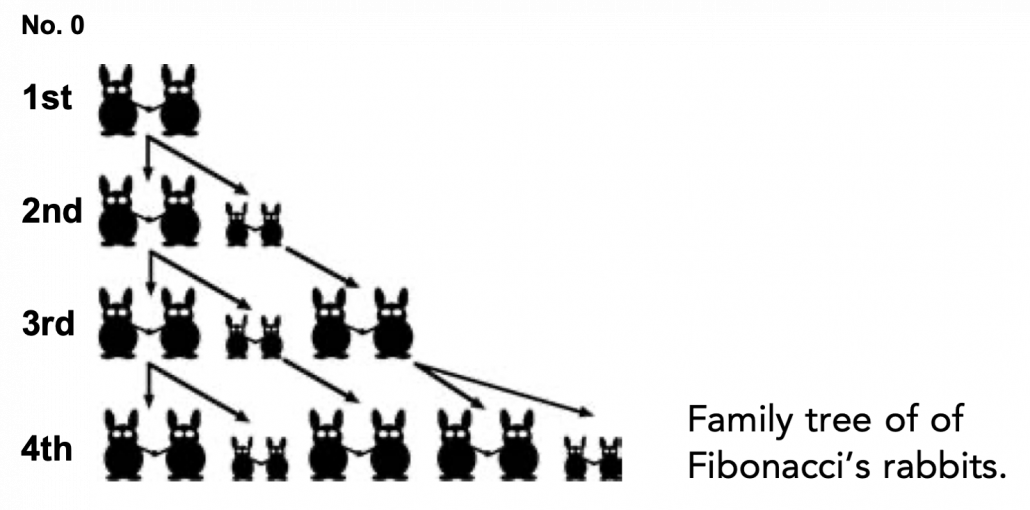
 be the number of pairs of grown up rabbits in the
be the number of pairs of grown up rabbits in the  generation. One pair of grown up rabbits produce one pair of young rabbit The concrete values of
generation. One pair of grown up rabbits produce one pair of young rabbit The concrete values of  are
are  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  . Assume that
. Assume that  and that
and that  , then you can calculate the number of the pairs of grown up rabbits in the next generation with the following recurrence relation.
, then you can calculate the number of the pairs of grown up rabbits in the next generation with the following recurrence relation.  .Let
.Let  be
be  , then the recurrence relation can be written as
, then the recurrence relation can be written as  , and the transition of
, and the transition of 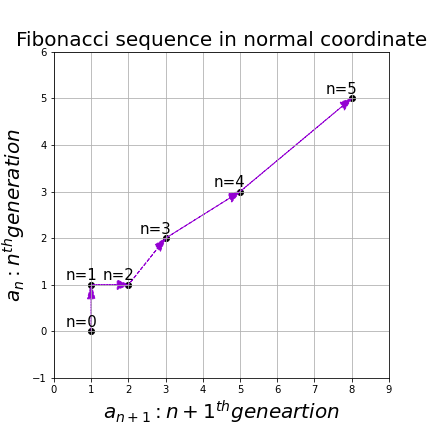
 are eigen values of
are eigen values of  are eigen vectors belonging to them respectively. Also let
are eigen vectors belonging to them respectively. Also let  scalars such that
scalars such that  . According to the definition of eigen values and eigen vectors belonging to them, the following two equations hold:
. According to the definition of eigen values and eigen vectors belonging to them, the following two equations hold:  . If you calculate
. If you calculate  is, using eigen vectors of
is, using eigen vectors of  . In the same way,
. In the same way,  , and
, and  . These equations show that in coordinate system made by eigen vectors of
. These equations show that in coordinate system made by eigen vectors of 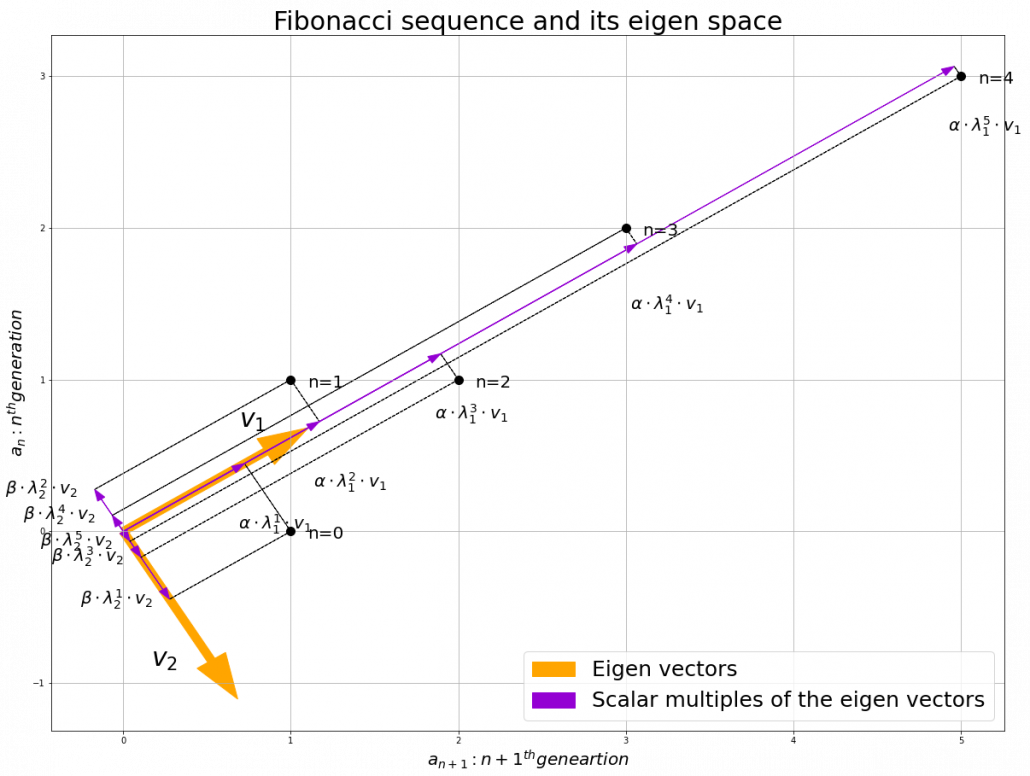
 for all values of the vector
for all values of the vector  for all the eigen values
for all the eigen values  .
. for all values of the vector
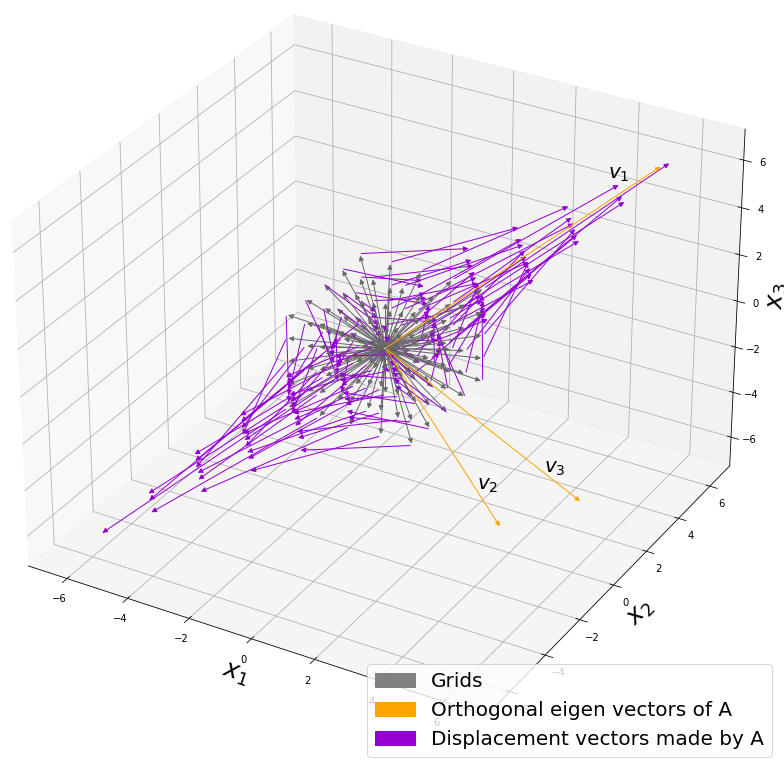
for all values of the vector  square positive semidefinite matrix
square positive semidefinite matrix  , whose linear transformation I visualized the second section, is also positive semidefinite.
, whose linear transformation I visualized the second section, is also positive semidefinite. . I visualized the displacement vectors made by the
. I visualized the displacement vectors made by the  .
.
 , where
, where  . In other words column vectors
. In other words column vectors  form an orthonormal coordinate system.
form an orthonormal coordinate system. . Combining this fact with what I have told you so far, you we can reach one conclusion that you can orthogonalize a real symmetric matrix
. Combining this fact with what I have told you so far, you we can reach one conclusion that you can orthogonalize a real symmetric matrix  is also orthonormal. In other words, assume
is also orthonormal. In other words, assume  ,
,  also forms a orthonormal coordinate system.
also forms a orthonormal coordinate system. expands or contracts vectors along each axis. I am going to explain that more precisely in the upcoming articles.
expands or contracts vectors along each axis. I am going to explain that more precisely in the upcoming articles. ', va='center',ha='right', fontsize=fontsize + 10)
plt.text(eigen_vectors.T[1][0] - small_shift, eigen_vectors.T[1][1],r'
', va='center',ha='right', fontsize=fontsize + 10)
plt.text(eigen_vectors.T[1][0] - small_shift, eigen_vectors.T[1][1],r' ', va='center',ha='right', fontsize=fontsize + 10)
for i in range(total_step):
plt.arrow(0, 0, v_1_list[i+1][0], v_1_list[i+1][1], head_width=0.05, color='darkviolet', length_includes_head=True)
plt.arrow(0, 0, v_2_list[i+1][0], v_2_list[i+1][1], head_width=0.05, color='darkviolet', length_includes_head=True)
plt.text(v_1_list[i+1][0] + 2*small_shift , v_1_list[i+1][1]-2*small_shift,r'
', va='center',ha='right', fontsize=fontsize + 10)
for i in range(total_step):
plt.arrow(0, 0, v_1_list[i+1][0], v_1_list[i+1][1], head_width=0.05, color='darkviolet', length_includes_head=True)
plt.arrow(0, 0, v_2_list[i+1][0], v_2_list[i+1][1], head_width=0.05, color='darkviolet', length_includes_head=True)
plt.text(v_1_list[i+1][0] + 2*small_shift , v_1_list[i+1][1]-2*small_shift,r' '.format(1,i+1, 1),va='center',ha='right', fontsize=fontsize)
plt.text(v_2_list[i+1][0]-0.1, v_2_list[i+1][1],r'
'.format(1,i+1, 1),va='center',ha='right', fontsize=fontsize)
plt.text(v_2_list[i+1][0]-0.1, v_2_list[i+1][1],r' '.format(2, i+1, 2),va='center',ha='right', fontsize=fontsize)
plt.arrow(v_1_list[i+1][0], v_1_list[i+1][1], v_2_list[i+1][0], v_2_list[i+1][1], head_width=0, color='black', linestyle='--', length_includes_head=True)
plt.arrow(v_2_list[i+1][0], v_2_list[i+1][1], v_1_list[i+1][0], v_1_list[i+1][1], head_width=0, color='black', linestyle='--', length_includes_head=True)
orange_patch = mpatches.Patch(color='orange', label='Eigen vectors')
purple_patch = mpatches.Patch(color='darkviolet', label='Scalar multiples of the eigen vectors')
plt.legend(handles=[orange_patch, purple_patch], fontsize=25, loc='lower right')
for i in range(total_step):
plt.text(x[i][0]+0.1, x[i][1]-0.05, r'n={0}'.format(i), fontsize=20)
plt.grid(True)
plt.ylabel("
'.format(2, i+1, 2),va='center',ha='right', fontsize=fontsize)
plt.arrow(v_1_list[i+1][0], v_1_list[i+1][1], v_2_list[i+1][0], v_2_list[i+1][1], head_width=0, color='black', linestyle='--', length_includes_head=True)
plt.arrow(v_2_list[i+1][0], v_2_list[i+1][1], v_1_list[i+1][0], v_1_list[i+1][1], head_width=0, color='black', linestyle='--', length_includes_head=True)
orange_patch = mpatches.Patch(color='orange', label='Eigen vectors')
purple_patch = mpatches.Patch(color='darkviolet', label='Scalar multiples of the eigen vectors')
plt.legend(handles=[orange_patch, purple_patch], fontsize=25, loc='lower right')
for i in range(total_step):
plt.text(x[i][0]+0.1, x[i][1]-0.05, r'n={0}'.format(i), fontsize=20)
plt.grid(True)
plt.ylabel(" ", fontsize=20)
plt.xlabel("
", fontsize=20)
plt.xlabel(" ", fontsize=20)
plt.title("Fibonacci sequence and its eigen space", fontsize=30)
#plt.savefig("Fibonacci_eigen_space.png")
plt.show()
", fontsize=20)
plt.title("Fibonacci sequence and its eigen space", fontsize=30)
#plt.savefig("Fibonacci_eigen_space.png")
plt.show()
 ', fontsize=20)
ax.text(eigen_vectors.T[1][0]*8 , eigen_vectors.T[1][1]*8, eigen_vectors.T[1][2]*8, r'
', fontsize=20)
ax.text(eigen_vectors.T[1][0]*8 , eigen_vectors.T[1][1]*8, eigen_vectors.T[1][2]*8, r' ', fontsize=20)
ax.text(eigen_vectors.T[2][0]*8 , eigen_vectors.T[2][1]*8, eigen_vectors.T[2][2]*8, r'
', fontsize=20)
ax.text(eigen_vectors.T[2][0]*8 , eigen_vectors.T[2][1]*8, eigen_vectors.T[2][2]*8, r' ', fontsize=20)
grey_patch = mpatches.Patch(color='grey', label='Grids')
orange_patch = mpatches.Patch(color='orange', label='Orthogonal eigen vectors of A')
purple_patch = mpatches.Patch(color='darkviolet', label='Displacement vectors made by A')
plt.legend(handles=[grey_patch, orange_patch, purple_patch], fontsize=20, loc='lower right')
ax.set_xlabel(r'
', fontsize=20)
grey_patch = mpatches.Patch(color='grey', label='Grids')
orange_patch = mpatches.Patch(color='orange', label='Orthogonal eigen vectors of A')
purple_patch = mpatches.Patch(color='darkviolet', label='Displacement vectors made by A')
plt.legend(handles=[grey_patch, orange_patch, purple_patch], fontsize=20, loc='lower right')
ax.set_xlabel(r' ', fontsize=25)
ax.set_ylabel(r'
', fontsize=25)
ax.set_ylabel(r' ', fontsize=25)
ax.set_zlabel(r'
', fontsize=25)
ax.set_zlabel(r' ', fontsize=25)
#plt.savefig("symmetric_positive_definite_visualizaiton.png")
plt.show()
', fontsize=25)
#plt.savefig("symmetric_positive_definite_visualizaiton.png")
plt.show()