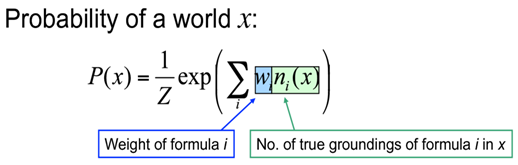
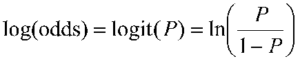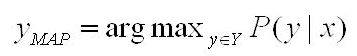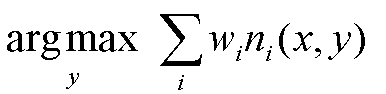Understanding the “simplicity” of reinforcement learning: comprehensive tips to take the trouble out of RL
*I adjusted mathematical notations in this article as close as possible to “Reinforcement Learning:An Introduction.” This book by Sutton and Barto is said to be almost mandatory for those who studying reinforcement learning. Also I tried to avoid as much mathematical notations, introducing some intuitive examples. In case any descriptions are confusing or unclear, informing me of that via posts or email would be appreciated.
Preface
First of all, I have to emphasize that I am new to reinforcement learning (RL), and my current field is object detection, to be more concrete transfer learning in object detection. Thus this article series itself is also a kind of study note for me. Reinforcement learning (RL) is often briefly compared with human trial and errors, and actually RL is based on neuroscience or psychology as well as neural networks (I am not sure about these fields though). The word “reinforcement” roughly means associating rewards with certain actions. Some experiments of RL were conducted on animals, which are widely known as Skinner box or more classically Pavlov’s Dogs. In short, you can encourage animals to do something by giving foods to them as rewards, just as many people might have done to their dogs. Before animals find linkages between certain actions and foods as rewards to those actions, they would just keep trial and errors. We can think of RL as a family of algorithms which mimics this behavior of animals trying to obtain as much reward as possible.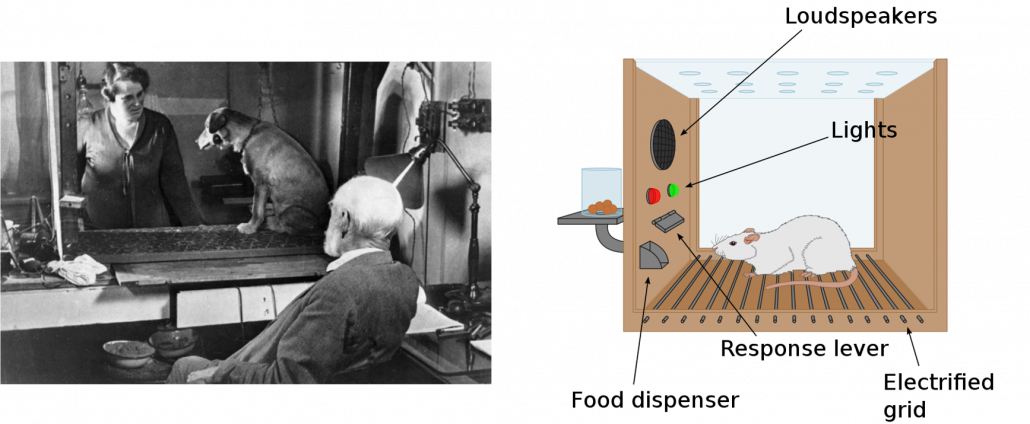
*My cats will not all the way try to entertain me to get foods though.
RL showed its conspicuous success in the field of video games, such as Atari, and defeating the world champion of Go, one of the most complicated board games. Actually RL can be applied to not only video games or board games, but also various other fields, such as business intelligence, medicine, and finance, but still I am very much fascinated by its application on video games. I am now studying the field which could bridge between the world of video games and the real world. I would like to mention this in the one of upcoming articles.
So far I got an impression that learning RL ideas would be more challenging than learning classical machine learning or deep learning for the following reasons.
- RL is a field of how to train models, rather than how to design the models themselves. That means you have to consider a variety of problem settings, and you would often forget which situation you are discussing.
- You need prerequisites knowledge about the models of components of RL for example neural networks, which are usually main topics in machine/deep learning textbooks.
- It is confusing what can be learned through RL depending on the types of tasks.
- Even after looking over at formulations of RL, it is still hard to imagine how RL enables computers to do trial and errors.
*For now I would like you to keep it in mind that basically values and policies are calculated during in during RL.
And I personally believe you should always keep the following points in your mind in order not to be at a loss in the process of learning RL.
- RL basically can be only applied to a very limited type of situation, which is called Markov decision process (MDP). In MDP settings your next state depends only on your current state and action, regardless of what you have done so far.
- You are ultimately interested in learning decision making rules in MDP, which are called policies.
- In the first stage of learning RL, you consider surprisingly simple situations. They might be simple like mazes in kids’ picture books.
- RL is in its early days of development.
Let me explain a bit more about what I meant by the third point above. I have been learning RL mainly with a very precise Japanese textbook named 「機械学習プロフェッショナルシリーズ 強化学習」(Machine Learning Professional Series: Reinforcement Learning). As I mentioned in an article of my series on RNN, I sometimes dislike Western textbooks because they tend to beat around the bush with simple examples to get to the point at a more abstract level. That is why I prefer reading books of this series in Japanese. And especially the RL one in the series was especially bulky and so abstract and overbearing to a spectacular degree. It had so many precise mathematical notations without leaving room for ambiguity, thus it took me a long time to notice that the book was merely discussing simple situations like mazes in kids’ picture books. I mean, the settings discussed were so simple that they can be expressed as tabular data, that is some Excel sheets.
*I could not notice that until the beginning of 6th chapter out of eight out of 8 chapters. The 6th chapter discusses uses of function approximators. With the approximations you can approximate tabular data. My articles will not dig this topic of approximation precisely, but the use of deep learning models, which I am going to explain someday, is a type of this approximation of RL models.
You might find that so many explanations on RL rely on examples of how to make computers navigate themselves in simple mazes or in playing video games, which are mostly impractical in the real world. However, as I will explain later, these are actually helpful examples to learn RL. As I show later, the relations of an agent and an environment are basically the same also in more complicated tasks. Reading some code or actually implementing RL would be very effective, especially in order to know simplicity of the situations in the beginning part of RL textbooks.
Given that you can do a lot of impressive and practical stuff with current deep learning libraries, you might get bored or disappointed by simple applications of RL in many textbooks. But as I mentioned above, RL is in its early days of development, at least at a public level. And in order to show its potential power, I am going to explain one of the most successful and complicated application of RL in the next article: I am planning to explain how AlphaGo or AplhaZero, RL-based AIs enabled computers to defeat the world champion of Go, one of the most complicated board games.
*RL was not used to the chess AI which defeated Kasparov in 1997. Combination of decision trees and super computers, without RL, was enough for the “simplicity” of chess. But uses of decision tree named Monte Carlo Tree Search enabled Alpha Go to read some steps ahead more effectively. It is said deep learning enabled AlphaGo to have intuition about games. Mote Carlo Tree Search enabled it to have abilities to predict some steps ahead, and RL how to learn from experience.
1. What is RL?
In conclusion I would interpret RL as follows: RL is a sub-field of training AI models, and optimal rules for decision makings in an environment are learned through RL, weakly supervised by rewards in a certain period of time. When and how to evaluate decision makings are task-specific, and they are often realized by trial-and-error-like behaviors of agents. Rules for decision makings are called policies in contexts of RL. And optimization problems of policies are called sequential decision-making problems.
You are more or less going to see what I meant by my definition throughout my article series.
*An agent in RL means an entity which makes decisions, interacting with the environment with an action. And the actions are made based on policies.
You can find various types of charts explaining relations of RL with AI, and I personally found the chart below the most plausible.
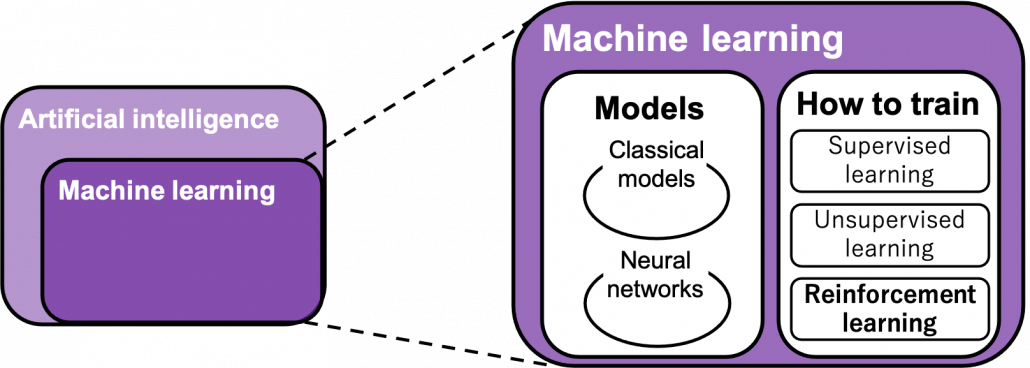 “Models” in the chart are often hyped as “AI” in media today. But AI is a more comprehensive field of trying to realize human-like intellectual behaviors with computers. And machine learning have been the most central sub-field of AI last decades. Around 2006 there was a breakthrough of deep learning. Due to the breakthrough machine learning gained much better performance with deep learning models. I would say people have been calling popular “models” in each time “AI.” And importantly, RL is one field of training models, besides supervised learning and unsupervised learning, rather than a field of designing “AI” models. Some people say supervised learning or unsupervised learning are more preferable than RL because currently these trainings are more likely to be more successful in wide range of fields than RL. And usually the more data you have the more likely supervised or unsupervised learning are.
“Models” in the chart are often hyped as “AI” in media today. But AI is a more comprehensive field of trying to realize human-like intellectual behaviors with computers. And machine learning have been the most central sub-field of AI last decades. Around 2006 there was a breakthrough of deep learning. Due to the breakthrough machine learning gained much better performance with deep learning models. I would say people have been calling popular “models” in each time “AI.” And importantly, RL is one field of training models, besides supervised learning and unsupervised learning, rather than a field of designing “AI” models. Some people say supervised learning or unsupervised learning are more preferable than RL because currently these trainings are more likely to be more successful in wide range of fields than RL. And usually the more data you have the more likely supervised or unsupervised learning are.
*The word “models” are used in another meaning later. Please keep it in mind that the “models” above are something like general functions. And the “models” which show up frequently later are functions modeling environments in RL.
*In case you’re totally new to AI and don’t understand what “supervising” means in these contexts, I think you should imagine cases of instructing students in schools. If a teacher just tells students “We have a Latin conjugation test next week, so you must check this section in the textbook.” to students, that’s a “supervised learning.” Students who take exams are “models.” Apt students like machine learning models would show excellent performances, but they might fail to apply the knowledge somewhere else. I mean, they might fail to properly conjugate words in unseen sentences. Next, if the students share an idea “It’s comfortable to get together with people alike.” they might be clustered to several groups. That might lead to “cool guys” or “not cool guys” group division. This is done without any explicit answers, and this corresponds to “unsupervised learning.” In this case, I would say a certain functions of the students’ brain or atmosphere there, which put similar students together, were the “models.” And finally, if teachers tell the students “Be a good student,” that’s what I meant with “weakly supervising.” However most people would say “How?” RL could correspond to such ultimate goals of education, and as well as education, you have to consider how to give rewards and how to evaluate students/agents. And “models” can vary. But such rewards often shows unexpected results.
2. RL and Markov decision process
As I mentioned in a former section, you have to keep it in mind that RL basically can be applied to a limited situation of sequential decision-making problems, which are called Markov decision processes (MDP). A markov decision process is a type of process where the next state of an agent depends only on the current state and the action taken in the current state. I would only roughly explain MDP in this article with a little formulation.
You might find MDPs very simple. But some people would find that their daily lives in fact can be described well with a MDP. The figure below is a state transition diagram of everyday routine at an office, and this is nothing but a MDP. I think many workers also basically have only four states “Chat” “Coffee” “Computer” and “Home” almost everyday. Numbers in black are possibilities of transitions at the state, and each corresponding number in orange is the reward you get when the action is taken. The diagram below shows that when you just keep using a computer, you would likely to get high rewards. On the other hand chatting with your colleagues would just continue to another term of chatting with a probability of 50%, and that undermines productivity by giving out the reward of -1. And having some coffee is very likely to lead to a chat. In practice, you optimize which action to take in each situation. You adjust probabilities at each state, that is you adjust a policy, through planning or via trial and error.
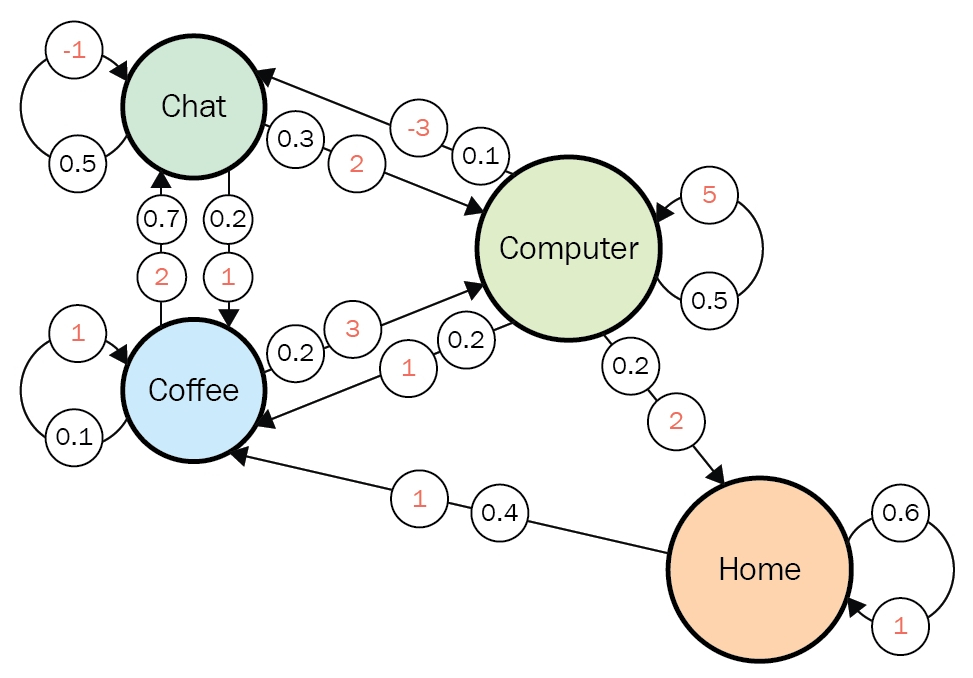
Source: https://subscription.packtpub.com/book/data/9781788834247/1/ch01lvl1sec12/markov-decision-processes
*Even if you say “Be a good student,” school kids in puberty they would act far from Markov decision process. Even though I took an example of school earlier, I am sure education should be much more complicated process which requires constant patience.
Of course you have to consider much more complicated MDPs in most RL problems, and in most cases you do not have known models like state transition diagrams. Or rather I have to say RL enables you to estimate such diagrams, which are usually called models in contexts of RL, by trial and errors. When you study RL, for the most part you will see a chart like below. I think it is important to understand what this kind of charts mean, whatever study materials on RL you consult. I said RL is basically a training method for finding optimal decision making rules called policies. And in RL settings, agents estimate such policies by taking actions in the environment. The environment determines a reward and the next state based on the current state and the current action of the agent.
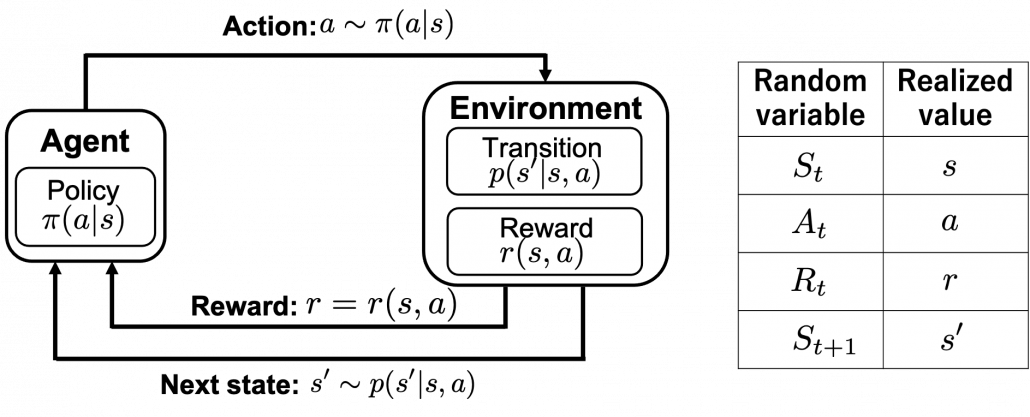
Let’s take a close look at the chart above in a bit mathematical manner. I made it based on “Machine Learning Professional Series: Reinforcement Learning.” The agent exert an action  in the environment, and the agent receives a reward
in the environment, and the agent receives a reward  and the next state
and the next state  . and
. and  are consequences of taking the action in the state
are consequences of taking the action in the state  . The action is taken based on a conditional probability given , which is denoted as
. The action is taken based on a conditional probability given , which is denoted as  . This probability function is the very function representing policies, which we want to optimize in RL.
. This probability function is the very function representing policies, which we want to optimize in RL.
*Please do not think too much about differences of  and
and  in the chart. Actions, rewards, or transitions of states can be both deterministic or probabilistic. In the chart above, with the notation
in the chart. Actions, rewards, or transitions of states can be both deterministic or probabilistic. In the chart above, with the notation  I meant that the action is taken with a probability of
I meant that the action is taken with a probability of  . And whether they are probabilistic or deterministic is task-specific. Also you should keep it in mind that all the values in the chart are realized values of random variables as I show in the chart at the right side.
. And whether they are probabilistic or deterministic is task-specific. Also you should keep it in mind that all the values in the chart are realized values of random variables as I show in the chart at the right side.
In the textbook “Reinforcement Learning:An Introduction” by Richard S. Sutton, which is almost mandatory for all the RL learners, RL process is displayed as the left side of the figure below. Each capital letter in the chart means a random variable. Relations of random variables can be also displayed as graphical models like the right side of the chart. The graphical model is a time series expansion of the chart of RL loops at the left side. The chart below shows almost the same idea as the one above. Whether they use random variables or realized values is the only difference between them. My point is that decision makings are simplified in RL as the models I have explained. Even if some situations are not strictly MDPs, in many cases the problems are approximated as MDPs in practice so that RL can be applied to. 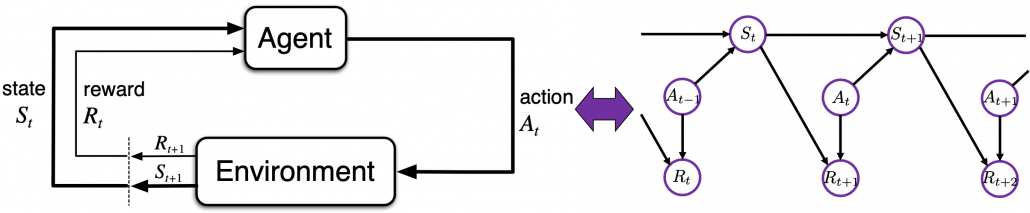
*I personally think you do not have to care so much about differences of random variables and their realized values in RL unless you discuss RL mathmematically. But if you do not know there are two types of notations, which are strictly different ideas, you might get confused while reading textboks on RL. At least in my artile series, I will strictly distinguish them only when their differences matter.
*In case you are not sure about differences of random variables and their realizations, please roughly grasp the terms as follows: random variables  are probabilistic tools for example dices. On the other hand their realized values
are probabilistic tools for example dices. On the other hand their realized values  are records of them, for example (4, 1, 6, 6, 2, 1, …). And the probability that a random variable takes on the value x is denoted as
are records of them, for example (4, 1, 6, 6, 2, 1, …). And the probability that a random variable takes on the value x is denoted as  . And
. And  means the random variable is selected from distribution
means the random variable is selected from distribution  . In case is a “dice,” for any
. In case is a “dice,” for any  .
.
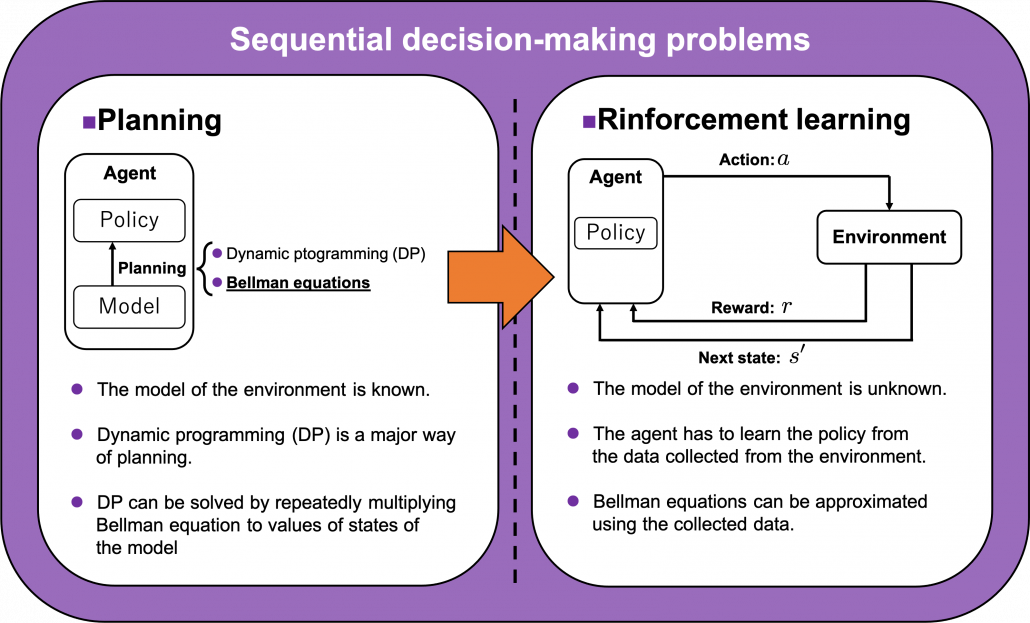
3. Planning and RL
We have seen RL is a family of training algorithms which optimizes rules for choosing  in sequential decision-making problems, usually assuming them to be MDPs. However I have to emphasize that RL is not the only way to optimize such policies. In sequential decision making problems, when the model of the environment is known, policies can be optimized also through planning without collecting data from the environment. On the other hand, when the model of the environment is unknown policies have to be optimized based on data which an agents collects from the environment through trial and errors. This is the very case called RL. You might find planning problems very simple and unrealistic in practical cases. But RL is based on planning of sequential decision-making problems with MDP settings, so studying planning problems is inevitable. As far as I could see so far, RL is a family of algorithms for approximating techniques in planning problems through trial and errors in environments. To be more concrete, in the next article I am going to explain dynamic programming (DP) in RL contexts as a major example of planning problems, and a formula called the Bellman equation plays a crucial role in planning. And after that we are going to see that RL algorithms are more or less approximations of Bellman equation by agents sampling data from environments.
in sequential decision-making problems, usually assuming them to be MDPs. However I have to emphasize that RL is not the only way to optimize such policies. In sequential decision making problems, when the model of the environment is known, policies can be optimized also through planning without collecting data from the environment. On the other hand, when the model of the environment is unknown policies have to be optimized based on data which an agents collects from the environment through trial and errors. This is the very case called RL. You might find planning problems very simple and unrealistic in practical cases. But RL is based on planning of sequential decision-making problems with MDP settings, so studying planning problems is inevitable. As far as I could see so far, RL is a family of algorithms for approximating techniques in planning problems through trial and errors in environments. To be more concrete, in the next article I am going to explain dynamic programming (DP) in RL contexts as a major example of planning problems, and a formula called the Bellman equation plays a crucial role in planning. And after that we are going to see that RL algorithms are more or less approximations of Bellman equation by agents sampling data from environments.
As an intuitive example, I would like to take a case of navigating a robot, which is explained in a famous textbook on robotics named “Probabilistic Robotics”. In this case, the state set  is the whole space on the map where the robot can move around. And the action set is
is the whole space on the map where the robot can move around. And the action set is  . If the robot does not fail to take any actions or there are no unexpected obstacles, manipulating the robot on the map is a MDP. In this example, the robot has to be navigated from the start point as the green dot to the goal as the red dot. In this case, blue arrows can be obtained through planning or RL. Each blue arrow denotes the action taken in each place, following the estimated policy. In other words, the function
. If the robot does not fail to take any actions or there are no unexpected obstacles, manipulating the robot on the map is a MDP. In this example, the robot has to be navigated from the start point as the green dot to the goal as the red dot. In this case, blue arrows can be obtained through planning or RL. Each blue arrow denotes the action taken in each place, following the estimated policy. In other words, the function  is the flow of the blue arrows. But policies can vary even in the same problem. If you just want the robot to reach the goal as soon as possible, you might get a blue arrows in the figure at the top after planning. But that means the robot has to pass a narrow street, and it is likely to bump into the walls. If you prefer to avoid such risks, you should adopt policies of choosing wider streets, like the blue arrows in the figure at the bottom.
is the flow of the blue arrows. But policies can vary even in the same problem. If you just want the robot to reach the goal as soon as possible, you might get a blue arrows in the figure at the top after planning. But that means the robot has to pass a narrow street, and it is likely to bump into the walls. If you prefer to avoid such risks, you should adopt policies of choosing wider streets, like the blue arrows in the figure at the bottom.
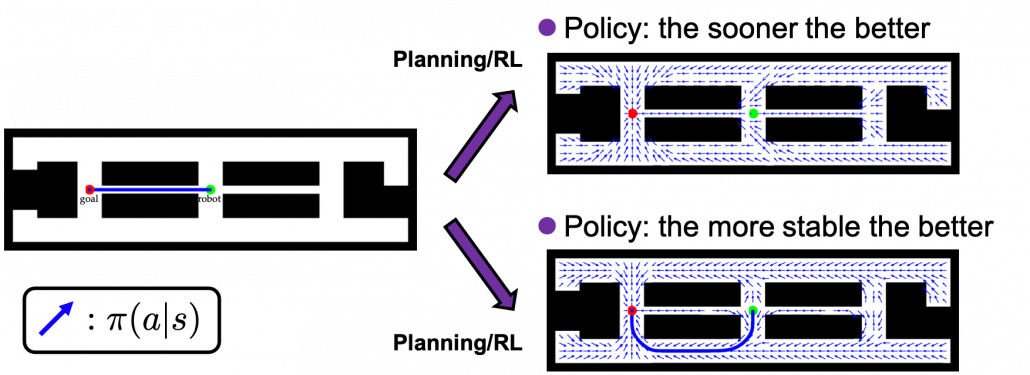
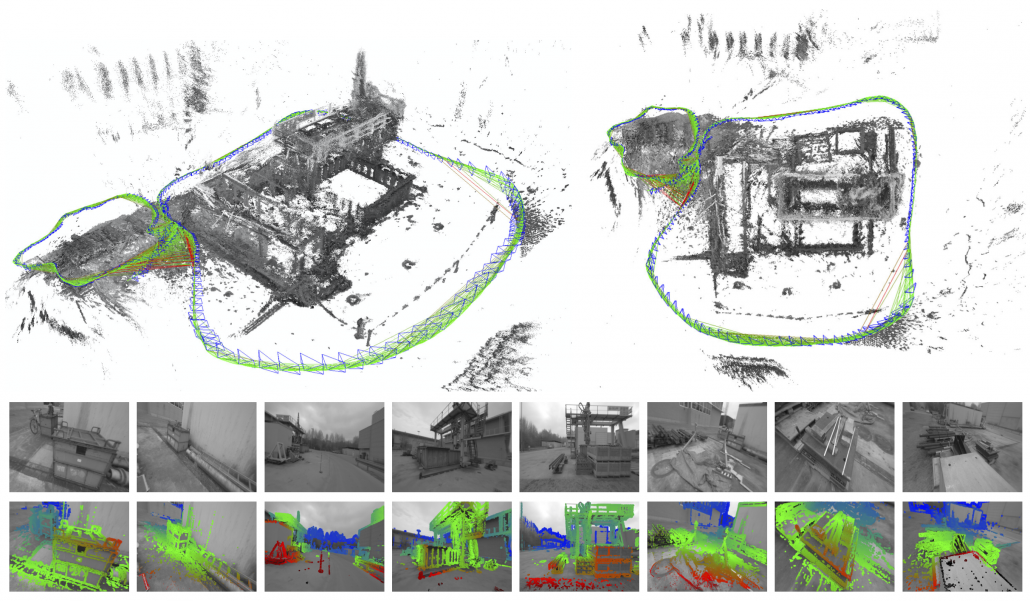
*In the textbook on probabilistic robotics, this case is classified to a planning problem rather than a RL problem because it assumes that the robot has a complete model of the environment, and RL is not introduced in the textbook. In case of robotics one major way of making a model, or rather a map is SLAM (Simultaneous Localization and Mapping). With SLAM, a map of the environment can be made only based on what have been seen with a moving camera like in the figure below. Half the first part of the textbook is about self localization of robots and gaining maps of environments. And the latter part is about planning in the gained map. RL is also based on planning problems as I explained. I would say RL is another branch of techniques to gain such models/maps and proper plans in the environment through trial and errors.
In the example of robotics above, we have not considered rewards  in the course of navigating the agent. That means the reward is given only when it reaches the goal. But agents can get lost if they get a reward only at the goal. Thus in many cases you optimize a policy such that it maximizes the sum of rewards
in the course of navigating the agent. That means the reward is given only when it reaches the goal. But agents can get lost if they get a reward only at the goal. Thus in many cases you optimize a policy such that it maximizes the sum of rewards  , where
, where  is the the length of the whole sequence of MDP in this case. More concretely, at every time step
is the the length of the whole sequence of MDP in this case. More concretely, at every time step  , agents have to estimate
, agents have to estimate  . The
. The  is called a return. But you usually have to consider uncertainty of future rewards, so in practice you multiply a discount rate
is called a return. But you usually have to consider uncertainty of future rewards, so in practice you multiply a discount rate  with rewards every time step. Thus in practice agents estimate a discounted return every time step as follows.
with rewards every time step. Thus in practice agents estimate a discounted return every time step as follows.

If agents blindly try to maximize immediate upcoming rewards in a greedy way, that can lead to smaller amount of rewards in the long run. Policies in RL have to be optimized so that they maximize return, a sum of upcoming rewards , every time step. But still, it is not realistic to take all the upcoming rewards  directly into consideration. These rewards have to be calculated recursively and probabilistically every time step. To be exact values of states are calculated this way. The value of a state in contexts of RL mean how likely agents get higher values if they start from the state. And how to calculate values is formulated as the Bellman equation.
directly into consideration. These rewards have to be calculated recursively and probabilistically every time step. To be exact values of states are calculated this way. The value of a state in contexts of RL mean how likely agents get higher values if they start from the state. And how to calculate values is formulated as the Bellman equation.
*If you are not sure what “ecursively” and “probabilistically” mean, please do not think too much. I am going to explain that as precisely as possible in the next article.
I am going to explain Bellman equation, or Bellman operator to be exact in the next article. For now I would like you to keep it in mind that Bellman operator calculates the value of a state by considering future actions and their following states and rewards. Bellman equation is often displayed as a decision-tree-like chart as below. I would say planning and RL are matter of repeatedly applying Bellman equation to values of states. In planning problems, the model of the environment is known. That is, all the connections of nodes of the graph at the left side of the figure below are known. On the other hand in RL, those connections are not completely known, thus they need to be estimated in certain ways by agents collecting data from the environment.
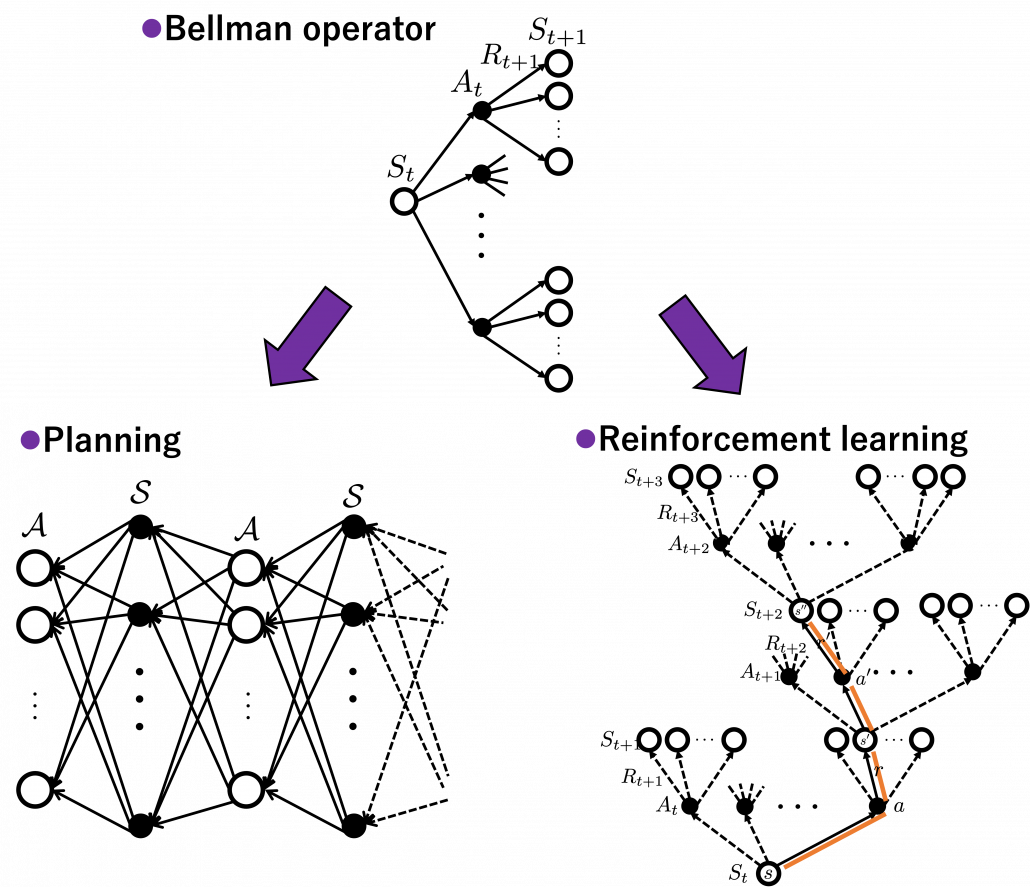
*I guess almost no one explain RL ideas as the graphs above, and actually I am in search of effective and correct ways of visualizing RL. But so far, I think the graphs above describe how values updated in RL problem settings with discrete data. You are going to see what these graphs mean little by little in upcoming articles. I am also planning to introduce Bellman operators to formulate RL so that you do not have to think about decision-tree-like graphs all the time.
4. Examples of how RL problems are modeled
You might find that so many explanations on RL rely on examples of how to make computers navigate themselves in simple mazes or play video games, which are mostly impractical in real world. But I think uses of RL in letting computers play video games are good examples when you study RL. The video game industry is one of the most developed and sophisticated area which have produced environments of RL. OpenAI provides some “playgrounds” where agents can actually move around, and there are also some ports of Atari games. I guess once you understand how RL can be modeled in those simulations, that helps to understand how other more practical tasks are implemented.
*It is a pity that there is no E.T. the Extra-Terrestrial. It is a notorious video game which put an end of the reign of Atari. And after that came the era of Nintendo Entertainment System.
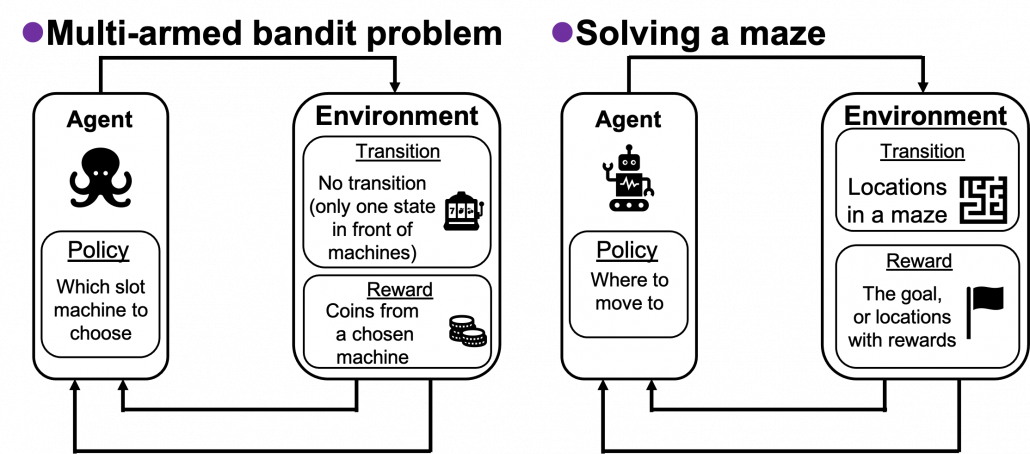
In the second section of this article, I showed the most typical diagram of the fundamental RL idea. The diagrams below show correspondences of each element of some simple RL examples to the diagram of general RL. Multi-armed bandit problems are a family of the most straightforward RL tasks, and I am going to explain it a bit more precisely later in this article. An agent solving a maze is also a very major example of RL tasks. In this case states  are locations where an agent can move. Rewards
are locations where an agent can move. Rewards  are goals or bonuses the agents get in the course of the maze. And in this case
are goals or bonuses the agents get in the course of the maze. And in this case  .
.
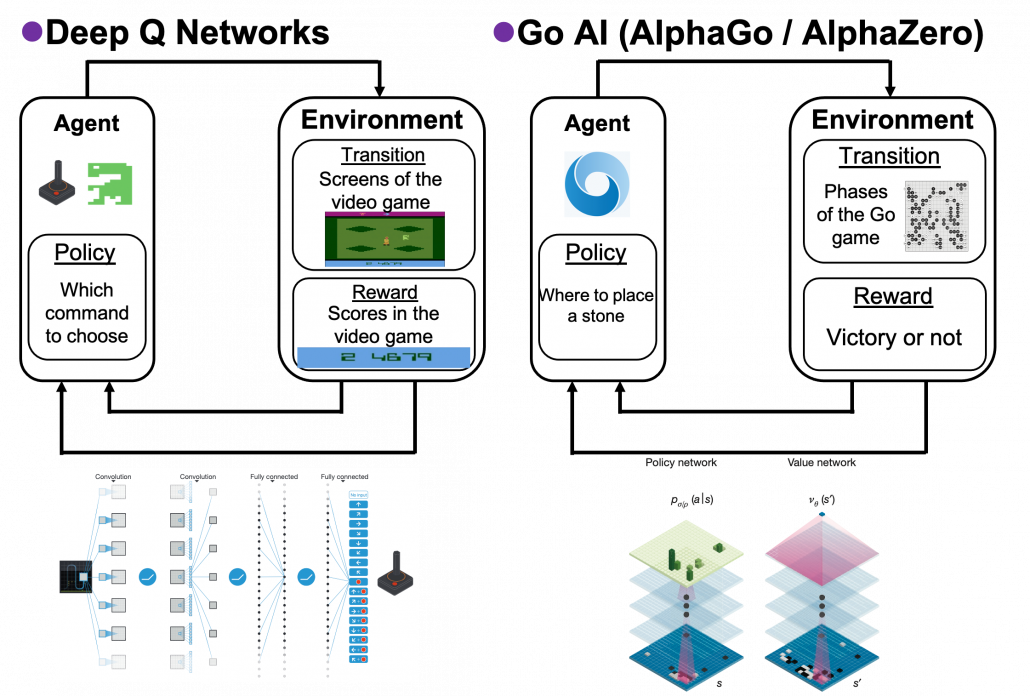
If the environments are more complicated, deep learning is needed to make more complicated functions to model each component of RL. Such RL is called deep reinforcement learning. The examples below are some successful cases of uses of deep RL. I think it is easy to imagine that the case of solving a maze is close to RL playing video games. In this case  is all the possible commands with an Atari controller like in the figure below. Deep Q Networks use deep learning in RL algorithms named Q learning. The development of convolutional neural networks (CNN) enabled computers to comprehend what are displayed on video game screens. Thanks to that, video games do not need to be simplified like mazes. Even though playing video games, especially complicated ones today, might not be strict MDPs, deep Q Networks simplifies the process of playing Atari as MDP. That is why the process playing video games can be simplified as the chart below, and this simplified MPD model can surpass human performances. AlphaGo and AlphaZero are anotehr successful cases of deep RL. AlphaGo is ther first RL model which defeated the world Go champion. And some training schemes were simplified and extented to other board games like chess in AlphaZero. Even though they were sensations in media as if they were menaces to human intelligence, they are also based on MDPs. A policy network which calculates which tactics to take to enhance probability of winning board games. But they use much more sophisticated and complicated techniques. And it is almost impossible to try training them unless you own a tech company or something with some servers mounted with some TPUs. But I am going to roughly explain how they work in one of my upcoming articles.
is all the possible commands with an Atari controller like in the figure below. Deep Q Networks use deep learning in RL algorithms named Q learning. The development of convolutional neural networks (CNN) enabled computers to comprehend what are displayed on video game screens. Thanks to that, video games do not need to be simplified like mazes. Even though playing video games, especially complicated ones today, might not be strict MDPs, deep Q Networks simplifies the process of playing Atari as MDP. That is why the process playing video games can be simplified as the chart below, and this simplified MPD model can surpass human performances. AlphaGo and AlphaZero are anotehr successful cases of deep RL. AlphaGo is ther first RL model which defeated the world Go champion. And some training schemes were simplified and extented to other board games like chess in AlphaZero. Even though they were sensations in media as if they were menaces to human intelligence, they are also based on MDPs. A policy network which calculates which tactics to take to enhance probability of winning board games. But they use much more sophisticated and complicated techniques. And it is almost impossible to try training them unless you own a tech company or something with some servers mounted with some TPUs. But I am going to roughly explain how they work in one of my upcoming articles.
5. Some keywords for organizing terms of RL
As I am also going to explain in next two articles, RL algorithms are totally different frameworks of training machine learning models compared to supervised/unsupervised learnig. I think pairs of keywords below are helpful in classifying RL algorithms you are going to encounter.
(1) “Model-based” or “model-free.”
I said planning problems are basics of RL problems, and in many cases RL algorithms approximate Bellman equation or related ideas. I also said planning problems can be solved by repeatedly applying Bellman equations on states of a model of an environment. But in RL problems, models are usually unknown, and agents can only move in an environment which gives a reward or the next state to an agent. The agent can gains richer information of the environment time step by time step in RL, but this procedure can be roughly classified to two types: model-free type and model-based type. In model-free type, models of the environment are not explicitly made, and policies are updated based on data collected from the environment. On the her hand, in model-based types the models of the environment are estimated, and policies are calculated based on the model.
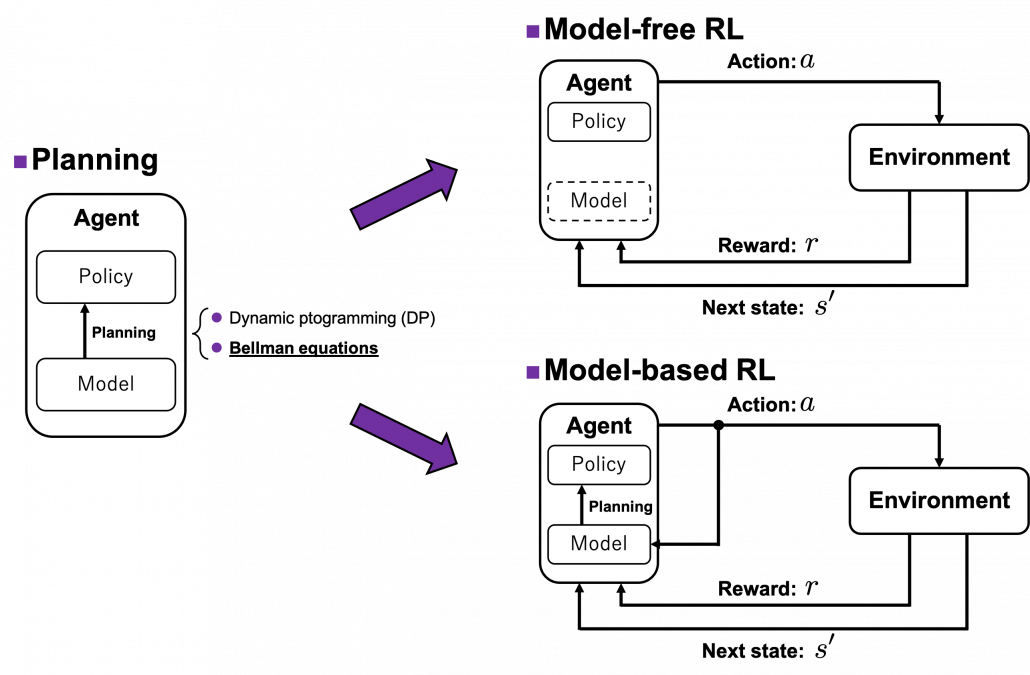
*AlphaGo and AlphaZero are examples of model-based RL. Phases of board games can be modeled with CNN. Plannings in this case correspond to reading some phases ahead of games, and they are enabled by Monte Carlo tree search. They are the only examples of model-based RL which I can come up with. And also I had an impression that many study materials on RL focus on model-free types of RL.
(2) “Values” or “policies.”
I mentioned that in RL, values and policies are optimized. Values are functions of a value of each state. The value here means how likely an agent gets high rewards in the future, starting from the state. Policies are functions fro calculating actions to take in each state, which I showed as each of blue arrows in the example of robotics above. But in RL, these two functions are renewed in return, and often they reach optimal functions when they converge. The figure below describes the idea well.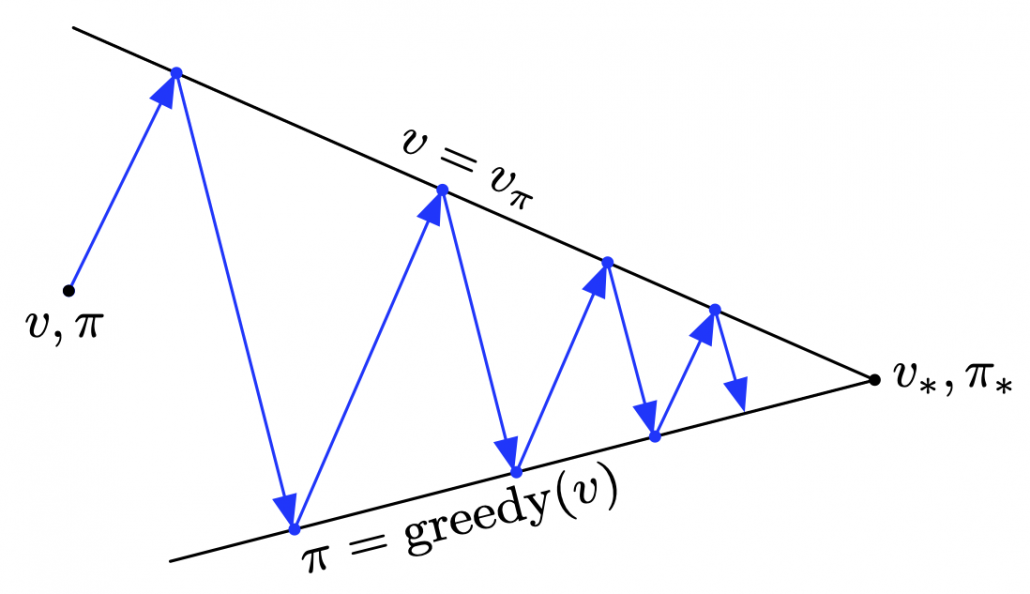
These are essential components of RL, and there too many variations of how to calculate them. For example timings of updating them, whether to update them probabilistically or deterministically. And whatever RL algorithm I talk about, how values and policies are updated will be of the best interest. Only briefly mentioning them would be just more and more confusing, so let me only briefly take examples of dynamic programming (DP).
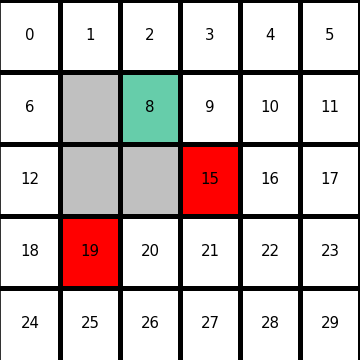
Let’s consider DP on a simple grid map which I showed in the preface. This is a planning problem, and agents have a perfect model of the map, so they do not have to actually move around there. Agents can move on any cells except for blocks, and they get a positive rewards at treasure cells, and negative rewards at danger cells. With policy iteration, the agents can interactively update policies and values of all the states of the map. The chart below shows how policies and values of cells are updated.
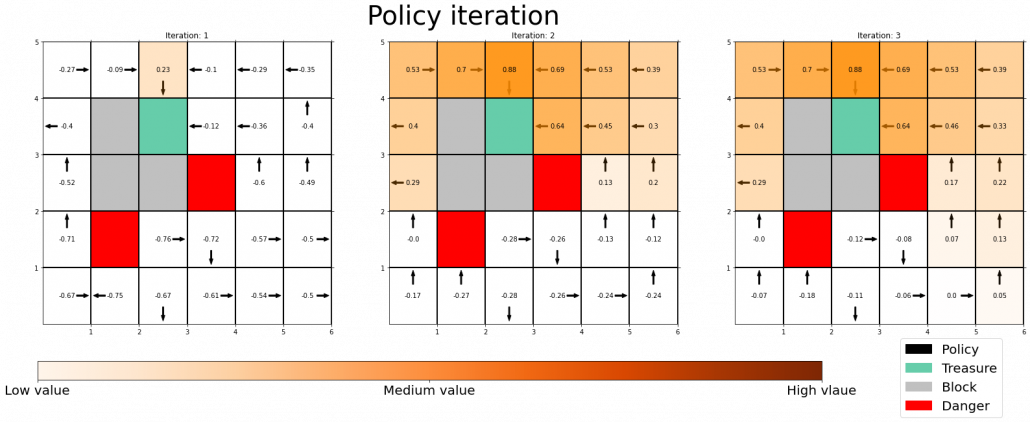
You do not necessarily have to calculate policies every iteration, and this case of DP is called value iteration. But as the chart below suggests, value iteration takes more time to converge.
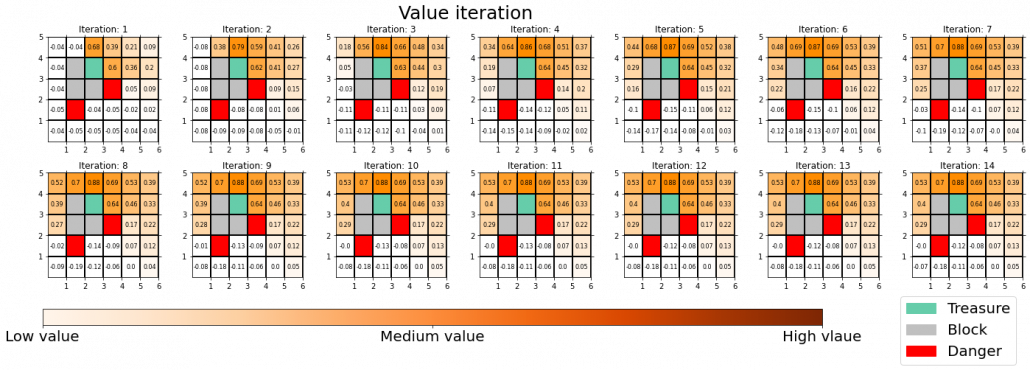
I am going to much more precisely explain the differences of values and policies in DP tasks in the next article.
(3) “Exploration” or “exploitation”
RL agents are not explicitly supervised by the correct answers of each behavior. They just receive rough signals of “good” or “bad.” One of the most typical failed cases of RL is that agents can be myopic. I mean, once agents find some actions which constantly give good reward, they tend to miss other actions which produce better rewards more effectively. One good way of avoiding this is adding some exploration, that is taking some risks to discover other actions.
I mentioned multi-armed bandit problems are simple setting of RL problems. And they also help understand trade-off of exploration and exploitation. In a multi-armed bandit problem, an agent chooses which slot machine to run every time step. Each slot machine gives out coins, or rewards with a probability of  . The number of trials is limited, so the agent has to find the machine which gives out coins the most efficiently within the limited number of trials. In this problem, the key is the balance of trying to find other effective slot machines and just trying to get as much coins as possible with the machine which for now seems to be the best. This is trade-off of “exploration” or “exploitation.” One simple way to implement exploration and exploitation trade-off is ɛ-greedy algorithm. This is quite simple: with a probability of
. The number of trials is limited, so the agent has to find the machine which gives out coins the most efficiently within the limited number of trials. In this problem, the key is the balance of trying to find other effective slot machines and just trying to get as much coins as possible with the machine which for now seems to be the best. This is trade-off of “exploration” or “exploitation.” One simple way to implement exploration and exploitation trade-off is ɛ-greedy algorithm. This is quite simple: with a probability of  , agents just randomly choose actions which are not thought to be the best then.
, agents just randomly choose actions which are not thought to be the best then.

*Casino owners are not so stupid. It is designed so that you would lose in the long run, and before your “exploration” is complete, you will be “exploited.”
Let’s take a look at a simple simulation of a multi-armed bandit problem. There are two “casinos,” I mean sets of slot machines. In casino A, all the slot machines gives out the same reward  , thus agents only need to find the machine which is the most likely to gives out more coins. But casino B is not simple like that. In this casino, slot machines with small odds give higher rewards.
, thus agents only need to find the machine which is the most likely to gives out more coins. But casino B is not simple like that. In this casino, slot machines with small odds give higher rewards.

I prepared four types of “multi-armed bandits,” I mean octopus agents. Each of them has each value of , and the s reflect their “curiosity,” or maybe “how inconsistent they are.” The graphs below show the average reward over 1000 simulations. In each simulation each agent can try slot machines 250 times in total. In casino A, it seems the agent with the curiosity of  gets the best rewards in a short term. But in the long run, more stable agent whose is
gets the best rewards in a short term. But in the long run, more stable agent whose is  , get more rewards. On the other hand in casino B, No on seems to make outstanding results.
, get more rewards. On the other hand in casino B, No on seems to make outstanding results.
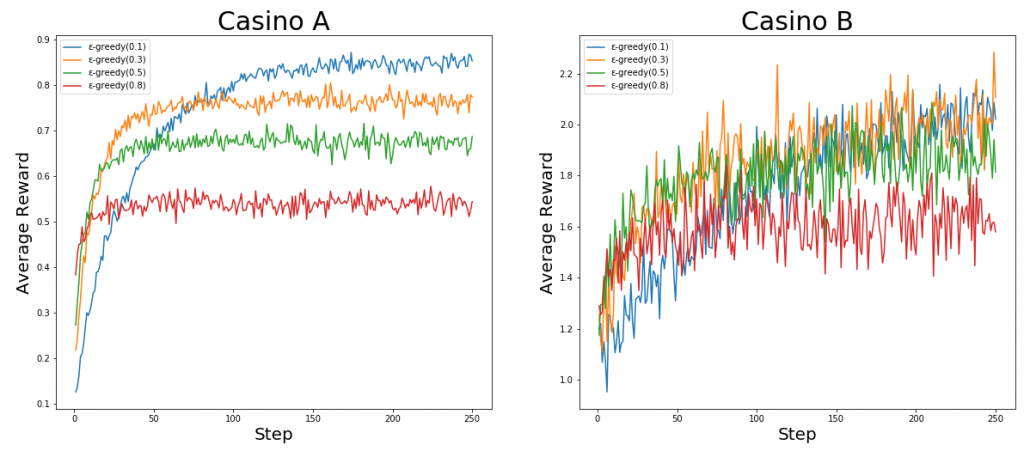
*I wold not concretely explain how values of each slot machines are updated in this article. I think I am going to explain multi-armed bandit problems with Monte Carlo tree search in one of upcoming articles to explain the algorithm of AlphaGo/AlphaZero.
(4)”Achievement” or “estimation”
The last pair of keywords is “achievement” or “estimation,” and it might be better to instead see them as a comparison of “Monte Carlo” and “temporal-difference (TD).” I said RL algorithms often approximate Bellman equation based on data an agent has collected. Agents moving around in environments can be viewed as sampling data from the environment. Agents sample data of states, actions, and rewards. At the same time agents constantly estimate the value of each state. Thus agents can modify their estimations of values using value calculated with sampled data. This is how agents make use of their “experiences” in RL. There are several variations of when to update estimations of values, but roughly they are classified to Monte Carlo and Temporal-difference (TD). Monte Carlo is based on achievements of agents after one episode or actions. And TD is more of based on constant estimation of values at every time step. Which approach is to take depends on tasks but it seems many major algorithms adopt TD types. But I got an impression that major RL algorithms adopt TD, and also it is said evaluating actions by TD has some analogies with how brain is “reinforced.” And above all, according to the book by Sutton and Barto “If one had to identify one idea as central and novel to reinforcement learning, it would undoubtedly be temporal-difference (TD) learning.” And an intermediate idea, between Monte Carlo and TD, also can be formulated as eligibility trace.
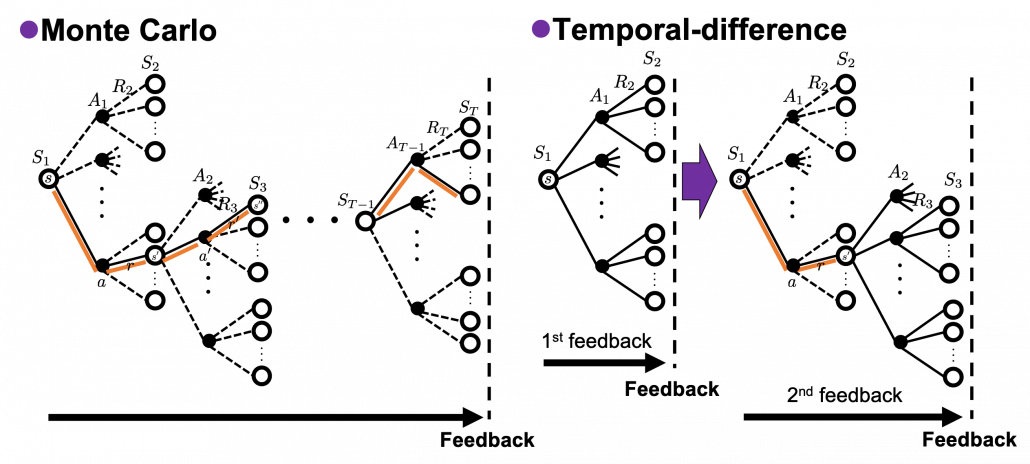
In this article I have briefly covered all the topics I am planning to explain in this series. This article is a start of a long-term journey of studying RL also to me. Any feedback on this series, as posts or emails, would be appreciated. The next article is going to be about dynamic programming, which is a major way for solving planning problems. In contexts of RL, dynamic programming is solved by repeatedly applying Bellman equation on values of states of a model of an environment. Thus I think it is no exaggeration to say dynamic programming is the backbone of RL algorithms.
Appendix
The code I used for the multi-armed bandit simulation. Just copy and paste them on Jupyter Notebook.
* I make study materials on machine learning, sponsored by DATANOMIQ. I do my best to make my content as straightforward but as precise as possible. I include all of my reference sources. If you notice any mistakes in my materials, including grammatical errors, please let me know (email: yasuto.tamura@datanomiq.de). And if you have any advice for making my materials more understandable to learners, I would appreciate hearing it.