K Nearest Neighbour For Supervised Learning
K-Nearest Neighbour (KNN) Algorithms is an easy-to-implement & advanced level supervised machine learning algorithm used for both – classification as well as regression problems. However, you can see a wide of its applications in classification problems across various industries.
If you’ve been shopping a lot in e-commerce sites like Amazon, Flipkart, Myntra, or love watching web series over Netflix and Amazon Prime, one common thing you’ve always noticed, and that is recommendations.
Are you wondering how they recommend you following your choice? They use KNN Supervised Learning to find out what you may need the next when you’re buying and recommend you with a few more products.
Imagine you’re looking for an iPhone to purchase. When you scroll down a little, you see some iPhone cases, tempered glasses – saying, “People who purchased an iPhone have also purchased these items. The same applies to Netflix and Amazon Prime. When you finished a show or a series, they give you recommendations of the same genre. And do it all using KNN supervised learning and classify the items for the best user experience.
Advantages Of KNN
- Quickest Calculation Time
- Simple Algorithms
- High Accuracy
- Versatile – best use for Regression and Classification.
- Doesn’t make any assumptions about data.
Where KNN Are Mostly Used
- Simple Recommendation Models
- Image Recognition Technology
- Decision-Making Models
- Calculating Credit Rating
Choosing The Right Value For K
To choose the right value of K, you have to run KNN algorithms several times with different values of K and select the value of K, which reduces the number of errors you’ve come across and come out as the most stable value for K.
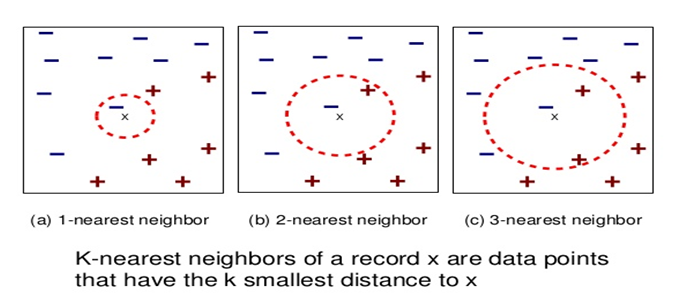
Your Step-By-Step Guide For Choosing The Value Of K
- As you decrease the value of K to 1 (K = 1), you’ll reach a query point, where you get to see many elements from class A (-) and class B (+) where (-) is the only nearest neighbor. Reasonably, you would think about the query point to be most likely the red one. As K =1, which has a blue color, KNN incorrectly predicts the wrong color blue.
- As you increase the value of K to 2 (K=2), you get to see two elements, (-) and (+) are the only nearest neighbor. As you have two values, which are of Class A and Class B, KNN incorrectly predicts the wrong values (Blue and Red).
- As you increase the value of K to 3 (K=3), you get to see three elements (-) and (+), (+) are the only nearest neighbor. And this time, you got three values, one from blue and two from red. As your assumption is red, KNN correctly predicts the right value (Blue and Red, Red). Your answer is more stable this time compared to previous ones.
Conclusion
KNN works by finding the nearest distance between a query and all the elements in the database. By choosing the value for K, we get the closest to the query. And then, KNN algorithms look for the most frequent labels in classification and averages of labels in regression.