Bias and Variance in Machine Learning
Machine learning continues to be an ever more vital component of our lives and ecosystem, whether we’re applying the techniques to answer research or business problems or in some cases even predicting the future. Machine learning models need to give accurate predictions in order to create real value for a given industry or domain.
While training a model is one of the key steps in the Data Science Project Life Cycle, how the model generalizes on unseen data is an equally important aspect that should be considered in every Data Science Project Life Cycle. We need to know whether it works and, consequently, if we can trust its predictions. Could the model be merely memorizing the data it is fed with, and therefore unable to make good predictions on future samples, or samples that it hasn’t seen before?
Let’s know the importance of evaluation with a simple example, There are two student’s Ramesh and Suresh preparing for the CAT exam to get into top IIMs (Indian Institute of Management). They both are quite good friends and stayed in the room during preparation and put an equal amount of hard work while solving numerical problems.
They both prepared for almost the same number of hours for the entire year and appeared in the final CAT exam. Surprisingly, Ramesh cleared, but Suresh did not. When asked, we got to know that there was one difference in their strategy of preparation between them, Ramesh had joined a Test Series course where he used to test his knowledge and understanding by giving mock exams and then further evaluating on which portions he is lagging and making necessary adjustments to he is preparation cycle in order to do well in those areas. But Suresh was confident, and he just kept training himself without testing on the preparation he had done.
Like the above situation we can train a Machine Learning Algorithm extensively with many parameters and new techniques, but if you are skipping its evaluation step, you cannot trust your model to perform well on the unseen data. In this article, we explain the importance of Bias, Variance and the trade-off between them in order to know how well a machine learning model generalizes to new, previously unseen data.
Bias
Bias is the difference between the Predicted Value and the Expected Value or how far are the predicted values from the actual values. During the training process the model makes certain assumptions on the training data provided. After Training, when it is introduced to the testing/validation data or unseen data, these assumptions may not always be correct.
If we use a large number of nearest neighbors in the K-Nearest Neighbors Algorithm, the model can totally decide that some parameters are not important at all for the modelling. For example, it can just consider that only two predictor variables are enough to classify the data point though we have more than 10 variables.
This type of model will make very strong assumptions about the other parameters not affecting the outcome at all. You can take it as a model predicting or understanding only the simple relationship when the data points clearly indicate a more complex relationship.
When the model has high bias error, it results in a very simplistic model that does not consider the complexity of the data very well leading to Underfitting.
Variance
Variance occurs when the model performs well on the trained dataset but does not do well on an unseen data set, it is when the model considers the fluctuations or i.e. the noise as in the data as well. The model will still consider the variance as something to learn from because it learns too much from the noise inside the trained data set that it fails to perform as expected on the unseen data.
Based on the above example from Bias, if the model learns that all the ten predictor variables are important to classify a given data point then it tends to have high variance. You can take it as the model is trying to understand every minute detail making it more complex and failing to perform well on the unseen data.
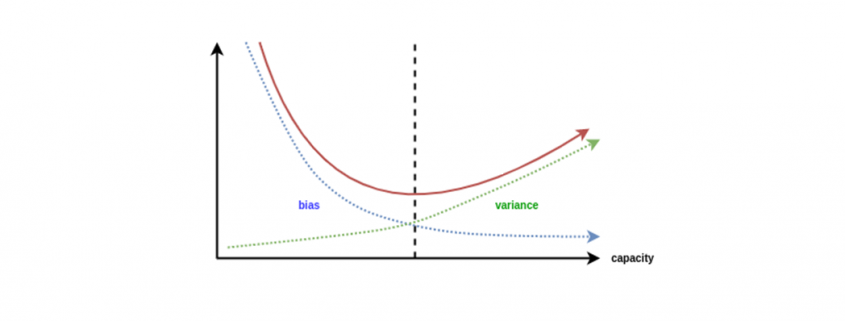
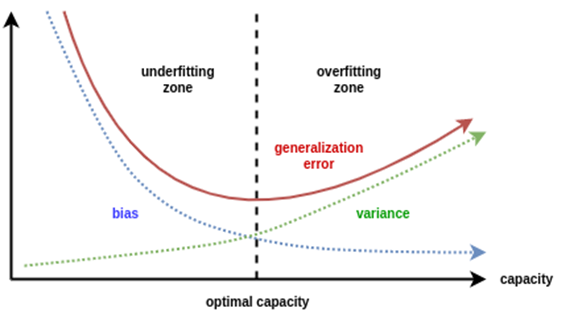
When a model has High Bias error, it underfits the data and makes very simplistic assumptions on it. When a model has High Variance error, it overfits the data and learns too much from it. When a model has balanced Bias and Variance errors, it performs well on the unseen data.
Bias-Variance Trade-off
Based on the definitions of bias and variance, there is clear trade-off between bias and variance when it comes to the performance of the model. A model will have a high error if it has very high bias and low variance and have a high error if it has high variance and low bias.
A model that strikes a balance between the bias and variance can minimize the error better than those that live on extreme ends.
We can find whether the model has High Bias using the below steps:
- We tend to get high training errors.
- The validation error or test error will be similar to the training error.
We can find whether the model has High Bias using the below steps:
- We tend to get low training error
- The validation error or test error will be very high.
We can fix the High Bias using below steps:
- We need to gather more input features or can even try to create few using the feature engineering techniques.
- We can even add few polynomial features in order to increase the complexity.
- If we are using any regularization terms in our model, we can try to minimize it.
We can fix the High Variance using below steps:
- We can gather more training data so that the model can learn more on the patterns rather than the noise.
- We can even try to reduce the input features or do feature selection.
- If we are using any regularization terms in our model we can try to maximize it.
Conclusion
In this article, we got to know the importance of the evaluation step in the Data Science Project Life Cycle, definitions of Bias and Variance, the trade-off between them and the steps we can take to fix the Underfitting and Overfitting of a Machine Learning Model.